Introduction
Welcome to manual for Austen, the parser generator. I hope you enjoy
reading this document; it currently has no set layout, but roughly progresses through
introduction, lexical analysis, basic grammar analysis, and then advanced grammar.
This
document is primarily meant to be the minimal place where all the features of Austen are
described, if not necessarily very well.
What does Austen do?
Austen is a parser generator. That is, a programmer who needs to
read text files in a certain format, would use Austen to build parsing code
in their language of choice (in this case, it's just Java for now), as
described more simply via another language specifically designed for
describing languages. But, you probably know that if you are reading this.
The important aspects of the current version of Austen is that it
uses a language that describes parsers based on Parsing Expression Grammars (PEGs) to describe the type of
text parsed, and that the current version includes a step of tokenization
of the text first. This is significant because firstly, PEGs are neat and
are a nice intuitive way to describe a language, but in contrast to
other PEG based tools (that I know of), Austen is a bit strange in
needing seperate tokenisation. I would argue that there are advantages to this
approach, and the drawbacks are few (even for combining languages). Having said that,
I am open to expanding Austen in the future to have a “scanner-less” mode.
The other important thing to note about Austen, before getting into a
few more specifics, is that Austen uses memorisation, in the fashion
of the Packrat parsing algorithm (developed by Brian Ford – see here for more information - and general PEG/Packrat bits). It does not
have to though, and one of its features is selective control over
memorisation. The current version does not allow easy exclusion of all
memorisation, but future versions will.
Prominent features in detail
The above is a very rough and uniformative description of Austen, and
probably does not excite the reader into wanting to further their use
of this tool. So, now comes the marketing spiel, with the significant
features, as I see them, highlighted. The following is
in no particular order.
Target language independence
Okay, the current version only outputs in Java, but the grammar description
files are target language neutral, and it is planned that future versions will
generate output in multiple languages, from the same grammar specification.
Java was initially chosen, as that is the language I most often use.
Seperate tokenization
At first this may seem to not be a feature, but a deficiency. One of the
selling points of PEGs is that they are scannerless. That is, a separate
tokenisation step is not necessarily required, as the rules that specify
the semantics can just as easily do the tokenization. So, why do I force
the user of Austen to use a separate tokenization step? Well, I do not
intend to always do this, but the initial version does, and it does this
because I feel that even though something might be able to do something,
does not mean it should.
Due to the nature of memorisation it seems, to me, bizzare to push up
the memory requirements to do silly things like tokenize key words, or
to include comments in parsing, when we could skip over that by an initial
tokenisation step. Yes, we limit some power for some esoteric languages,
but such situations do not occur to me, for typical use.
The major objection will come with composition of languages, where in
one language a word is a keyword, for example, but in another it is not.
Austen eats such problems for breakfast though, as the tokenisation
allows tokens to be of multiple types (such as a keyword, as well as an
identifier), and thus the composition ability of PEGs is not compromised
(or at least not for likely language compositions).
Left recursion, with priorities
One of the big plus points with Austen is that it handles left recursion
in rules. Yes, I know lots of PEG tools do that nowadays, but Austen is
significant for a number of reasons.
First, it works. For direct recursion, and indirect. And, it works whether
or not memorisation is used on a rule or not. And here is the killer, it
handles ordered left-recursion in a way that intuitive and useful, and
allows the user to neatly write left-recursive grammars, with right or
left associativity. I think this is very significant, because it makes
PEGs truely user-friendly and practical. But more on that later.
Extended PEGs
This is very cool stuff, though I'm not sure of the uses yet. Austen, as
said a number of times, is based on Parsing Expression Grammars, but extends
that specification further. All the standard operators are there, plus a
few syntactic sugar, but also the specification is extended with the
use of rule variables.
The tokenisation step assigns a type to tokens. They may be integers or
strings, or floats, or booleans. Given this, it is possible to write
grammars that interact more closely with the text being read, with
the parser interacting with read tokens, and using this to influence further
parsing. Skip to the later section on extended PEGs to get a look at what I mean.
Modular
Austen allows a modular approach to grammars (and tokenization), allow
library of useful language components to be built up.
What's new in Version 1.1
Version 1.1 has a bunch of new and exciting features. These include:
- Bug fixes to the extended PEG code. Previously there were some issues
using variables, and tagging them. This has been fixed.
- The inclusion of "start" and "end" blocks for LEX tokenising. This allows
lex style operations to occur at the beginning and end of parsing (click here
for more info).
- Lex operations extended, with the include of of "if-else" structures (click here
for more info).
- Token marking, and token reversing operations. This allows a user to mark a section of
tokens, to later be reversed (or deleted). This can be useful for intergrating right-to-left
sections within an overall left-to-right document (click here
for more info).
- User variables are allows for lex blocks, allowing parsing actions to be dependent on
user input values (click here
for more info).
- The use of user "interface" definitions, that are used in both tokenisation and packrat parsing,
to allow greater interaction with user code (click here first
for more info, and then here).
- The inclusion of system variables for getting access to line and character information
for lex tokenisation (click here
for more info).
- The inclusion of system variables for getting access to line and character information
for packrat parsing (click here
for more info).
- The ability to make non-memorisation the default in packrat parsing, with memorisation
the exception (click here
for more info).
- User variables are allows for packrat blocks, allowing parsing actions to be dependent on
user input values (click here
for more info). Mixed with the similar use with lex tokenisation allows for indentation
dependent parsing.
- The ability to provide hints for syntactic errors in the packrat parse (click here
for more info).
- The ability to match any token (click here
for more info).
Running Austen
Austen is provided as a jar (or source code for compiling if you are brave), and
as such, needs to be run with a command similar to:
java -jar Austen.jar [ options ] files
If no files are specified, then the simple graphical user interface will appear. Otherwise, if "-help" is
specified as an option then the following is outputted, and explains the available options:
Austen help (Austen --help)
Usage: Austen [OPTION]... [FILES]...
A parser generator for JAVA using Packrat Parsing, with PEG grammars, as well as lexical analysis via NFA based token parsing.
Options
--help - Show this message
-user [user path] - Sets alternative path for user files
-output [output path] - Sets alternative path for the output
-library [library path] - Sets alternative path for library files
-clean - clear target directories before outputing build results
The user must specify every file that is to produce output. Other Austen files may be accessed (via
the "import" option - see below), but unless specified, those files will not result in any generated
java code).
The "user path" is the default path for searching for files specified by "import". The
"output path" is the path where all generated code is stored. The "library path" is where files that
are shared across projects are stored.
The GUI interface
If no files or options are specified (or the jar is started simply by double-clicking), then a
simple GUI interface will appear. This looks similar to the following:

Operation should be reasonably straightforward. The main task is that three folders ought to be specified (two at the minimum).
The first is the "library" folder, which contains Austen files that are shared amongst projects. The second, the "source"
folder, is the folder where all the Austen files for a project sit. The vital difference between the two
folders is that in a build, only files from the "source" folder will acutally result in the creation of
any generated code. The library code must be generated seperately, by using it as the source in another project.
The third and final folder is the "target" folder, which is the base folder for the generated code. It
ideally should be a folder that is set aside entirely for code generated by Austen.
Once the "source" folder has been selected, the files in that folder should appear in the "Files" list.
Austen files should end in ".austen", or ".austenx" (either is fine).
The buttons on the right allow the compiling and building. Compiling is just for testing. The Austen files
will be read and interpreted, and any areas can be noted, but no code will be produced, even if there are no
errors.
The two build options do all that "Compile" does, but also produce code, if there are no errors. The
difference between the two is that "Build" overwrites files in the target folder, and leaves any generated files
that were there previously, but are not part of the new set of files. This can happen as a project changes, as
Austen produces a number of non-user files that are named in a sometimes inconsistent way. Using "Clean Build"
will result in the target folder being cleared of all files first (use wisely!).
The Log
The Log informs the user of the compilation/build progress (sorry, no fancy progress bars yet). The
output will be self-explanatory, though sometimes the errors given may be a bit strange (the error logging system
needs a bit of work), they should direct the user to problems reasonably well. Use the "Clear" button to clear
previous output.
Projects
There is support for a simple form of project. Once folders have been set up, they can be saved as a project
by using the "Save"/"Save As" option in the "File" menu. As expected, use "Open" to open a previously saved project,
and the "Recent" menu to quick load previously saved projects.
File format
There are a number of different types of parser objects defined within an Austen file, including tokens, lex,
and peg blocks. There is no special file for each, and all can occur in one file. An example file might look something
like this:
output example.parser;
tokens ExampleTokens {
...
}
lex ExampleLex tokens ExampleTokens uses ExampleDefs{
...
}
define library ExampleDefs {
...
}
peg ExamplePEG tokens ExampleTokens {
...
}
The above example shows the basic layout where all the parsing components are in the same file. The order of
declaration, in general, is not significant. The most
important line to take note of, before the finer details of the bulk of the file are examined, is the
first line:
output example.parser;
The Output Declaration
The output declaration specifies package information for where the generated code will go. This is
the most language specific part of Austen, and it would be nice to avoid it, but for now, it directly translates
to the root Java package where the generated source files will end up. The files will not end up in one package,
but each component will use a different sub package from the specified root.
It is possible to specify different root packages for different components. To do this, just issue a new
output declaration before the definition of the component of interest. The compiler will complain if no
output declaration has been made before a component that produces output (library definitions do not necessarily
produce code).
The fact that the output declaration translates directly to a Java concept is not something I
envisage as causing problems when more languages are added, as the package concept will map (I expect) in one way or another
to any language I am planning on adding.
The Import Declaration
While it is possible to put all the parser components into one file, it is not necessary. On large projects, it
may well be wise not to, in fact. To utilise the components declared in an external file, the import declaration is used.
The import declarations must be the first items in a file, and are of the form:
import namespace="Filename.austen";
The "namespace" is use for referencing external components within the file, and in general is used wherever a
component is referenced by prefacing the reference with the namespace name followed by a colon, ":". The follow example
shows the previous example split over two files:
TokensDefs.austen
output example.parser;
tokens ExampleTokens {
...
}
define library ExampleDefs {
...
}
Main.austen
import tokenDefs="TokensDefs.austen";
output example.parser;
lex ExampleLex tokens tokenDefs:ExampleTokens uses tokenDefs:ExampleDefs{
...
}
peg ExamplePEG tokens tokenDefs:ExampleTokens {
...
}
File storage/searching
External files can either come from the user (source) folder, or from the library folder. I'm not
sure if library folders are searched first, or user/source ones. You'll have to
check (behaviour will remain consistent in future versions...).
Comments
Comments in AustenX files follow the C-like language form. That is, there
are single line comments starting with "//", and block comments that start with
"/*", and end with "*/".
Tokens
The first step in creating an Austen parser is to define the tokenisation. This step itself can be broken down into two further components. The
first is a definition of what tokens are identified. This definition does not describe how the tokens are parsed. The second step,
which could in theory be provided by hand coding, or an external application, is scanner definition. This second step in Austen is
provided by a simple non-deterministic finite-automata based lexical analyser, in the tradition of that provided by Lexx,
and other similar programs.
Defining tokens
Token definition is provided in a tokens block. An example of such a block is as follows:
tokens Example {
String ID;
boolean BOOLEAN;
String STRING;
int NUMBER;
void PLUS_SYMBOL;
void MINUS_SYMBOL;
void WHALE_KEYWORD, STAR_SYMBOL, ASSIGNMENT;
String ERROR;
}
By my personal convention, token names are fully capitalised (with underscores to separate words). In the example above, a
list of tokens is given with the token type given first followed by the token name, followed (for this version) by a semi-colon;
A tokens block is just a list of all such tokens. A tokens block is marked by the keyword tokens followed by the name
of the block (in the above case, "Example"). The current valid types of a token are as follows:
- String, or string - a string of text
- int - an integer number (32 bit)
- double or float - a floating point number
- boolean - a boolean value that is either true or false
- void - no type (or token has no specific data attached)
As noted in the example, multiple tokens can be expressed at once, if they share the same type.
Library tokens
A library of tokens can be created to be reused in multiple token definitions. A library is defined in a similar way
to a normal tokens block except the key word library appears before the tokens keyword. So, for example,
the following is a simple library token definition:
library tokens Basics {
boolean BOOLEAN;
String STRING, ERROR;
int NUMBER;
}
A library tokens can be incorporated into a normal tokens block by having that block "extend" the library (hello Java),
such as in the following:
tokens Example2 extends Basic {
String ID;
void PLUS_SYMBOL;
void MINUS_SYMBOL, STAR_SYMBOL;
void WHALE_KEYWORD;
void ASSIGNMENT;
}
Given the definition of Basics, the definition of Example2 would essentially be identical with that
of Example. One cannot extend a non-library tokens definition, but multiple inheritences is possible, and a
library block may extend another library block. Again, I was a bit tricksy there, and included two token names on one line, which
is perfectly fine (as long as they have the same type).
Resulting generated code
When Austen is run with a tokens definition, some code is generated. For Java, this code will appear in
the sub package "lexi.tokens", from the base package (so if "output x.y;" occured earlier, the classes would appear
in the "x.y.lexi.tokens" package). There will be an "ErrorToken" interface, and a general token descriptor interface based
on the name of the tokens block (so, in the case of Example2, the resulting Java interface will be "Example2Token.java"). For
the most part, the end-user will not directly deal with these clasess.
Lexical analysis
Once a definition of the tokens used has been created, the next step
in tokenisation will be to create the "lexical scanner" for such tokens.
Multiple scanners could be created, as well as ones by hand, or perhaps using a third party tool.
In fact, no scanner need be created in order to move on
the next step of creating a PEG parser, but the resulting parser would
not be very useful (as it would know what tokens it needed, but nothing would be able to provide them). This
section will describe the lexical analysis currently provided by Austen.
The Lex Block
In Austen a lexical analyser is defined within a lex block. This block will look similar to the following:
lex MyLex tokens Example {
initial normal;
ALPHA = {'a'-'z'}|{'A'-'Z};
DIGIT = {'0'-'9'};
STRING_ALPHA = ALPHA|DIGIT|' ';
ALPHA_HEAD = ALPHA|'_';
ALPHA_TAIL = ALPHA_HEAD|'_';
mark baseMark;
mode simpleComment {
pattern ( "\n" ) { newline; switch normal; }
pattern ( . ) { }
}
mode normal {
pattern ( "+" ) { trigger PLUS_SYMBOL; }
pattern ( "-" ) { trigger MINUS_SYMBOL; }
pattern ( "*" ) { trigger STAR_SYMBOL; }
pattern ( "//" ) { switch simpleComment; }
pattern ( "\n" ) { newline; }
pattern ( {"\t"|" "} ) { }
pattern ( "true" ) { trigger BOOLEAN; }
pattern ( "false" ) { trigger BOOLEAN; }
pattern ( "whale" ) { trigger WHALE_KEYWORD & ID="whale"; }
pattern ( '"' $-start STRING_CHAR* $+end '"' ) {
trigger STRING = range(low=start,high=end);
}
pattern ( ALPHA_HEAD ALPHA_TAIL*) {
trigger ID;
}
pattern ( DIGIT+ '.' DIGIT+ ) {
trigger REAL;
}
pattern ( DIGIT+ ) {
trigger NUMBER;
}
}
}
The above example has a lot happening in it, so let's start with the first line:
lex MyLex tokens Example {
The lex keyword marks the start of the lexical analysier definition, and the following identifier is the name
(in this case "MyLex"), this is followed by the tokens keyword which is then followed by the name of the
tokens definition (in this case, we will use the "Example" tokens block described earlier). There is a little bit more
that can come after that, but we'll leave that to later. Let's turn now to the next line:
initial normal;
First, the semi-colon is (usually) optional; I just use it as force of habit. The main point of the initial declaration is
to tell Austen what "modes" the analyser starts out in. In this case, we've selected "normal" (which is defined later). I
chose to write mode names in lowerCamelCase. It is possible to list multiple starting modes, seperated by commas. I'm
not sure what the practical use of this might be, but it's there if you need it.
The next bits are where the important stuff happens. Patterns matched are defined within "mode" blocks,
which are "modes of parsing". Different modes allow the analyser to interpret text different depending on
what mode the anlyser is currently in (and due to NFA nature of the analyser, it can be in more than one mode - though
this is probably not something one would take advantage of).
The first mode defined is the "simpleComment" one, as follows:
mode simpleComment {
pattern ( "\n" ) { newline; switch normal; }
pattern ( . ) { }
}
The block starts with the mode keyword and is followed by the mode name, and then the usual curly brackets to
surround the mode definition. Within the mode block are a series of pattern delcarations, marked by the pattern keyword.
A pattern declaration is of the form:
pattern ( regular expression ) { actions to do on match }
In the above example, the first pattern matches "\n", which means the new line character (so the unix one - I'll get
to a better solution later). The actions, on matching a new line character are first, to mark a new line,
with the built-in newline command. The purpose of the newline command is to reset the internal line and character
counters, which are stored with each token. The second command is the switch command, which instructs the analyser to
switch modes, which in this case, is to the "normal" mode.
Triggering a token
Matching a token does not mean it is automatically stored. All the pattern matches in the "simpleComment" mode do not
store the matched text in any form. This is not surprising, as you've probably guessed, the "simpleComment" mode is somehow
linked to reading user comments, which a compiler probably is not interested in. The command that actually indicates that
a token should be stored is the trigger command. There is a few things to this command, but let's begin with a simple
example from the "normal" mode given above:
pattern ( "*" ) { trigger STAR_SYMBOL; }
In this example, the asterix, or "star symbol", has been matched, and the action uses the trigger command to
"trigger" the "STAR_SYMBOL" token, as defined in the tokens definition "Example". Looking back at the definition for "STAR_SYMBOL",
the type is void, so none of the input text is stored, but a token object is appended to the current list of tokens. All
tokens currently include information on the line number and character number (within the line) that the token was matched
at.
Trigger just means adding the specified token to the current list of tokens, but there is a little more to it than that.
First, a single match can trigger mutiple tokens in serial. That is, we could have written:
pattern ( "*" ) { trigger STAR_SYMBOL; trigger PLUS_SYMBOL; }
This would mean that for every "*" in the input, two tokens are added to the list of tokens. Furthermore, we
can add multiple tokens concurrently, or to be more honest, we can trigger a token with multiple "personalities". This
is done by using one trigger command but specifying multiple token names, such as the following:
pattern ( "*" ) { trigger STAR_SYMBOL, PLUS_SYMBOL; }
or...
pattern ( "*" ) { trigger STAR_SYMBOL & PLUS_SYMBOL; }
Using either a comma-seperated list, or an ampersand-seperated one is both acceptable. In either case, what is meant is
that the token triggered can be treated as either a "STAR_SYMBOL" or a "PLUS_SYMBOL". This combining of tokens is more
useful with keywords, as keywords can also be identifiers. So for example, the "whale" keyword is handled as:
pattern ( "whale" ) { trigger WHALE_KEYWORD & ID; }
The point of doing this will not become truely clear until later when we look at the PEG parsing component,
but essentially, it is to aid in providing some of the power of scannerless parsing that PEGs normally use, even
when using a scanner. As will be seen, PEG parsers, even with a seperate tokenisation step, can handle keywords in
a language as, for example, an identifier, depending on context (so in Java, with PEG parsing, a class could be
called "class" or "java", without too much trouble). Moreover, if we are combining languages, we can allow
keywords in one language, to be used as identifiers in another.
Assigning values with triggers
In the previous example, with the "whale" keyword, in the original example the line was actually as follows:
pattern ( "whale" ) { trigger WHALE_KEYWORD & ID = "whale"; }
The use of the assignment at the end of the trigger is important, especially when using tokens of type "void". For
non-void tokens they are assigned a value based on the parsed text. If the type is a non-string type then the assigned
value will be converted to the type specified. If a trigger is given for more than one token at once, and one is
void then it will not store the parsed text. The use of the assignment sets the value to a constant (in the
above example, "whale"). Otherwise, when that token is read as an "ID" it would be read as "void", and not "whale".
Ideally, one ought to assign constant values to all void tokens. (Future versions of Austen will do this
automatically for non-variable pattern matches; eg "cat", versus "ca*t", as explained later.)
General regular expression operators
Okay, we have described the basic matching of set text; to do this, just use the text to match surrounded by
double quotes. Regular expressions for pattern matching is usually more complex than that though, and the lexical analyser
in Austen is no different.
Matching single characters
First, it should be noted that single characters can also be matched by placing them
in single quote marks. You can match a double quote this way, and a single quote can be matched within a double-quoted
string (single quotes should really just be for multi-character strings like double quotes, and I suspect they will
be in the near future). You can also match escaped characters, such as '\n', to match new line characters (see above),
as well as provide explicity unicode values, just by using \45,for example, to match the character with code 45 (no
quotes needed, but can be used).
Next, it can be noted that any character can be matched with '.' (that's a full-stop, without the quotes).
Ranges can be matched by seperating them with a minus symbol. That is, 'a'-'z' matches all lowercase letters.
Matching repetitions
To match repetitions, as per normal, there is the "+" and "*" operators, which match one or more, and zero or more
respectively. That is, to match one or more of the first lowercase letter of the alphabet, use 'a'+.
The range operation (the minus bit) has higher precedence (see below, so to match all lowercase letters, zero or more times, use
'a'-'z'+.
Matching possibilities
If something is optional, use the "?" operator, or the "maybe" operator. For example, "cat" "dog"? "cat"
means match "cat" (must), followed possibly by "dog", and then certainly "cat" again (so "cat dog cat" or "cat cat").
If something must be matched, but it can be one of a number of options, than the "|", or "or" operator can be used.
This operator just seperates a list of possibilities. The longest match (and first in order) is the one used (it is not
a greedy match). So "cat" |"dog" |"frog" matches either "cat", "dog", or "frog". If "hell" | "hello" is used
on text "hello", then the token is parsed as "hello".
Combining operators,
one could use {"cat" |"dog"}+ |"frog", which means match one or more of either "cat" or "dog" (so,
"catcatdogcatdog" would match, or just match one "frog". But wait! What is with the brackets you ask? I don't get
that last example! Read on.
Blocks
To block matching elements together, just enclose them in "curly" brackets. That is, {'a' 'b'}+ means
match, one or more times, an 'a', followed by a 'b' (of course, you can just write that as "ab"+).
Another example would be {"cat" "dog"?}* "cat", which would match "cat", with a possible "dog", zero
or more times, followed by a final "cat" (so in this case, for every "dog" there must be a preceeding "cat", but for every
cat there need not be a "dog", and we must finish on a "cat").
Defines (or macros)
You may call them "macros", I have called them "defines", which may not be the best word, but mostly, it does matter. The point
of a define is to allow easy reuse of commonly used patterns. Patterns are stored in a define, and then just
used within the regular expressions by simply using the define's name. First, to define a define (macro):
ALPHA = {'a'-'z'}|{'A'-'Z};
Defines are placed with in the lex block, as root elements (that is, not within "mode" blocks). Defines can
refer to other defines (order is not important).
A simple example of the use of a define in the example lex block is:
pattern ( DIGIT+ ) {
trigger NUMBER;
}
This just means, a "NUMBER" token is triggered by one or more digits (which are anything between '0'-'9'). A more complex
example, which uses defines referencing defines (if you backtrack through the definitions) is:
pattern ( ALPHA_HEAD ALPHA_TAIL*) {
trigger ID;
}
Triggers, token types, and match text
Depending on the type of the token (as defined in the tokens block), data may be stored with
each token. The line number and character number of the token is stored with every token, but if the
token type is not void then data relating to the string matched for the token, is stored with
the token. If the type is int, this data is stored as a 32-bit integer, if it is string
then a string is stored (and so on).
Normally, the data stored is derived from the entire matched text,
and will be parsed according to type. That is, in the Java implementation, an integer value will be
obtained by calling Integer.parseInt() on the matched string. Sometimes though, only segments of the
matched string are required, and sometimes, values might want to be given directly. Another possibility is
that a different way of converting a string to an alternative primitive type might be required; currently, Austen
offers no way to do this, but rest assured, it is a very high priority, and will be incorporated soon (along with
the ability, hopefully, to define and handle more complex datatypes).
Going back to what Austen can do, the first thing that is useful, is being able to select portions of the matched
text to be used for the trigger. This is seen in the example in the handling of strings in the input (strings being
things in quotes here). In particular, examine the following:
pattern ( '"' $-start STRING_CHAR* $+end '"' ) {
trigger STRING = range(low=start,high=end);
}
In this case, the "STRING" token is being triggered, but the supplied data (indicated by the "=") is given as
a range between two points. Unfortunately, things get a little complex here. the position variables can be
placed in the matching expression, by marking them with "$".
The definition provided is actually a bit of overkill, so we will It would rewrite it as the following, returning to
the extra bits later:
pattern ( '"' $start STRING_CHAR* $end '"' ) {
trigger STRING = range(low=start,high=end);
}
In this case, "$start" means, set the "start" variable to the cursor position of the next read character, when
the analyser has progressed this far. The same occurs for the "end" variable, with "$end". In between these two
markers we match zero or more string characters, and it's this bit that we are interested in — not the double
quotes on the end. So, in the trigger command we set the trigger data to the range specified. This is
a built-in function (possibly the only function) that takes two parameters. Parameter order is not important,
as functions here only allow named parameters (I think — if not, I am not going to tell you because I would
rather you used the named form), where the "low" parameter is the beginning point, and "high" parameter is the end point (plus
one). The "$" is only used with variables within the regular expression.
Minimum/maximum match.
Returning to the way the "STRING" trigger rule is originally written it can be noted that the position variables
have an addition "+" or "-" mixed in (that is $-start, and $+end). The
astute amongst you may wonder what happens if the position variables are placed within in a block that could
be repeated multiple times. If the "-" is attached, the minimum position will be stored, if the "+" is attached,
the maximum position will be stored. I will not tell you the default behaviour (but I suspect it is the maximum
option), because it would be good form to put them in regardless (as I have here, even though it makes no difference,
as there is only ever one match for each position variable.
Referencing variables (version 1.1)
As of version 1.1 of AustenX, variables referenced in lex expressions may or may not have a "$" at the start. This
is to ensure consistency of appearance with the PEG use of variables (without breaking version 1.0 code). So, for example, the following is also valid:
pattern ( '"' $start STRING_CHAR* $end '"' ) {
trigger STRING = range(low=$start,high=$end);
}
Pattern Actions
The "trigger" command is an example of a pattern action — the things that happen when a pattern is
matched (or in, start/end blocks). There are a number of other action
commands that may be used. In all cases the semi-colon at the end of the action is not required.
The switch action
One action mentioned so far is the "switch" command. This allows the user
to switch the finaite state automata to a different mode (or modes). It consists of
the keyword "switch" followed a the name of the mode to switch to. Currently only one mode
is allowed to be used at a time, but I recall an earlier version being able to switch to multiple
modes — maybe this will reappear in a future version.
The print/debug commands
Two commands are supplied to allow printing of information while doing the lex parse, for the
intended purpose of debuging. The format for print is "print" ( [expressions] ), where [expressions]
is a comma seperated list of suitable expressions print (the most straightforward being "strings"). For debug, it use "print" ( [expressions] ).
Both debug and print work the same, except debug prints via the simple Debug framework in the Solar project, that basically prepends class
and line number of the caller to the outputed text. For example:
pattern ("cat") { print("cat",1); }
pattern ("dog") { debug("dog"); }
The "if" statement (v1.1 on)
From version 1.1 of AustenX there is also an "if" statement, which works roughly like "if" in most
langauges (certainly Java). The format is "if ( [expression] ) [statement]
, followed
by an option "else" clause (eg,
"else" [statement] ). For example:
pattern ("cat") {
if(utils.firstCat()) {
trigger ID="cat1"
} else
trigger ID="cat2";
}
Note, the use of utils.firstCat() is explained in the section on types and variables.
Statement block (v1.1 on)
New with version 1.1 is the ability to block statements by surrounding them with curly brackets (like
c-like languages). This only really has an effect for the "if" statement (see above).
The "mark" and "reverse from" actions (v1.1 on)
The marking mechanisms are discussed later.
The "newline" action
This is described elsewhere, and advances the line marker by one, and resets the character marker.
Method calls
With the introduction of class definitions, it is now possible to
interact with user code directly in the lexical (and packrat) parsing. This follows a similar format
to other languages, except in passing parameters. Essentially, a method is called by naming
the related variable, a full stop symbol, and then the name of the method to call, followed
by the parameters in brackets (like one would do in Java). Consider the following example:
class Test {
void meow();
}
lex MyLex(Test t) tokens Example {
...
pattern("cat") {
trigger ID="cat";
t.meow();
}
...
}
In the above example, the "meow" method was called on the "t" variable, when the pattern "cat"
was matched. When the method has parameters, those can be supplied in any order but require
tagging with name (like Rust). So, with parameters, an example would be:
class Test2 {
void woof(int x, String name);
}
lex MyLex(Test2 t) tokens Example {
...
pattern("cat") {
trigger ID="cat";
t.woof(name: "cat", x: 4);
}
...
}
Order and matching
Patterns are matched to the longest match, and if the same length, to the first defined. If a rule is never
matched, because prior rules cover all possibilities, than an error is generated. For example:
pattern ( "He" "l"+ "o" ) {} //Rule A
pattern ( "Hell" "o"? ) { } // Rule B
pattern ( "Hell" ) { } // Rule C
In this case, the text "Hello", would be matched by rule A, even though rule B can match it too (because rule A is defiend
before rule B), and rule C would generate an error, because it will never match anything, because "Hell" is "caught" by rule B.
If the order of rule C and B is swapped the compiler should then reject rule B, because all strings that B matches ("Hell", and "Hello")
are matched by previous rules (A for "Hello", C for "Hell").
Modularity for lexical analysis
There are two parts to modularity for the lexical analysis. The first is around libraries for define macros. The second
is for the pattern matching itself.
Define macro libraries
To create a library of define macros that you might want to reuse in your projects, you can create a define library block. An example
of such a thing is as follows:
define library GeneralDefs {
STRING_ALPHA = {ALPHA|DIGIT|" "|"'"};
ALPHA = {{'a'-'z'}|{'A'-'Z'}};
DIGIT = {'0'-'9'};
ALPHA_HEAD = {ALPHA|'_'};
ALPHA_TAIL = {ALPHA_HEAD|DIGIT};
NEWLINE = {"\r"|"\n"|"\r\n"};
}
The above define library specifies the define macros used in our example lex block. Sneakily placed within that define library is a better pattern for matching new-line characters, which will work
across all platforms. To substitute
them in, we use the uses keyword in the lex definition. That is, we would change to the following:
lex MyLex tokens Example uses GeneralDefs{
...
}
More than one define library maybe referenced; they just need to be seperated by commas (after the uses keyword).
Pattern libraries
As libraries of define macros can be created, so too can libraries of patterns matched (and their resulting operations).
To do this we use a patter library declaration, such as:
pattern library Strings tokens Example uses GeneralDefs {
pattern ( '"' $-start STRING_CHAR* $+end '"' ) {
trigger STRING = range(low=start,high=end);
}
}
Basically, what goes within a pattern library is what would go within a mode block within a lex
declaration. You cannot, yet, create libraries that have more than one mode. Like lex declarations, a
pattern library is connected with a tokens declarations, and may use external define libraries, like
a lex block.
To include a pattern library within a lex declaration is slightly different to other modular features,
where the inclusion is done in the "header" of the declaration. Because order is important, inclusion is done "inline" so
as to indicate which matches are of higher importance, and which are of lower importance. We do this with the
library keyword, and an example would be to switch in our "Strings" library into are well worked example lex block as
follows:
lex MyLex tokens Example uses GeneralDefs {
...
mode normal {
...
pattern ( "whale" ) { trigger WHALE_KEYWORD & ID; }
library Strings();
pattern ( ALPHA_HEAD ALPHA_TAIL*) {
trigger ID;
}
...
}
}
Thus, the important bit is:
library Strings();
You will notice the two round brackets, which make things look like parameters can be passed. This is explained later
in the section on user variables.
The last final thing to note is that the tokens used by the pattern library must be compatible with the
tokens used by the lex declaration. Remembering that a tokens declaration can extended other tokens
declarations, the pattern library must either use the same tokens block as the lex block, or one of the
extended library tokens block. Pattern libraries, unlike lex blocks, can use library based tokens declarations.
Multiple matches
One last thing that needs to be mentioned is what happens when more than one rule matches some text. Like usual
lexical analysers, two things that matter are firstly, what pattern matches the longest bit of text, and second, what pattern
came first. So basically, assuming I have some input text "cats like hats", if I have one pattern that matches "cat", and one that matches "cats", the one that matches "cats" will
be the one used, regardless of order. If I have two patterns that match "cat" (but not "cats"), then whatever rule is listed first is the
one that is used. This is why library patterns are specified inline - where the library reference goes indicates what patterns should
overide the library ones, and what patterns are overiding by the library.
Lastly, one final note of importance. If one pattern complete occludes another pattern from ever being matched, Austenx will currently
stop and produce an error. Thus, the following will produce an error:
pattern ("c"? "a"* "t" "s"?) { }
pattern ("cat") { }
This is because on the text "cat" the second pattern is never used (and that's the only thing it can match), because
the first rule will match "cat" first. The following is not an error:
pattern ("c"? "a"* "t" "s"?) { }
pattern ("cat" "s"*) { }
This is not an error, because "catsss" is matched by the second rule, but not by the first. Also, this further example is
not an error:
pattern ("cat") { }
pattern ("c"? "a"* "t" "s"?) { }
The above example, seems very similar, but the order is changed. Now, if the input is "cat" (and not "cats"), then
the first pattern will match (and so will the second), but the order counts, and the first is taken. The second pattern is
not completely occluded by the first, as there is other input it can match, not covered by "cat" (eg. "aaaats").
Advanced lexical analysis
This section details more advanced features of the lexical analysis (introduced from version 1.1 onwards).
Marks and token reversing
New as of version 1.1 are tools for marking tokens and reversing tokens. The point of this is
to allow right-to-left parsing, in a left-to-right framework (or perhaps more likely, top-to-bottom one).
By that, I mean reading right-to-left text that has be delimited by new lines (that go down the
page), or having sections within the language that switch direction. The facilities required for this
are the mark declaration and setting, and the "reverse from" action.
Declaring marks
To use a mark it must be declared first. This is done outside of modes, at the "root" of the lex
definition (see the original example, for a declaration of a "baseMark" mark". The
format of a mark declaration is just the "mark" keyword, followed by a comma-seperated list of mark
identifiers (more than one mark declaration can occur if that is preferred). So for example (the semi-colon is optional):
mark happy, sad;
Setting a mark
Setting a mark occurs inside an action/statement block (like the pattern match actions). It
uses a similar syntax to the mark declaration (except currently only one mark identifier per mark
statement). So for example:
pattern ("cat") { mark happy; }
pattern ("dog") { mark sad; }
Reversing from a mark
Again, the reversing from a mark statement occurs inside an action/statement block, like setting a mark.
It has the rather verbose syntax of "reverse" "from" [mark name], so for example:
pattern ("cat") { mark happy; }
pattern ("dog") { reverse from happy; }
The above example would place a mark when "cat" was matched, and then, when a "dog" is matched,
reverse all the intermediate tokens.
Start and end blocks
New as of version 1.1 are some additional elements of a lex block for doing actions outside of
matching text. Currently there are two optional blocks for specifying what should be done at the
start of parsing, before any characters are examined, (the start block) and what is to be done at the end when
all characters have been matched (the end block).
Usage
Start and end blocks appear outside of modes at the moment (this may change in the future),
and currently should not include an "switch" statements to change modes. They follow the format
"start" { [actions] }, where [actions] is a set of actions (like "trigger"
etc), as would appear in a pattern match. So for example:
lex MyLex tokens Example {
initial normal;
...
end {
trigger ID="END OF FILE!";
print("The end!");
}
mode simpleComment { ... }
...
start {
trigger ID="Start OF FILE!";
print("It begins!");
}
}
Note, start and end blocks can be defined after or before other elements, and multiple blocks
can be defined - they will just be executed in order in the final generated code. Currently,
they probably do not work in library blocks (future feature!).
User supplied variables
An important feature added to lex (and packrat) parsing in version 1.1 is the ability to pass
information to the parsing processes from the calling user code. The basic type of variables
are "primitive" ones that are just string, integer, boolean, or double values. With lex blocks
the user supplied parameters are specified at the start of the lex definition (similar to how a
method/function in c-like languages might do it). So for example:
lex WithArgs(int x, string y) tokens Example {
...
}
In the previous example, the lexical analysier called MyLex takes two parameters: a interger
called "x", and a string called "y". Variables in this case are typed (and the names follow
what is used in Java, though one can use "string", or "String" for string types). This changes the
user generated code such that, with Java code generation, the generated WithArgsLexParser class has the following
constructor:
public class WithArgsLexParser {
...
public WithArgsLexParser(int xValue, String yValue) {
...
}
...
}
The supplied values can then be used in the parsing action blocks within the lex parser (eg,
the matching actions, or in the start/end blocks). One simple example using a boolean variable
might be for conditional actions to be taken in parsing, based on user code, not at compile time.
So for example:
lex Conditional(boolean doCat, String catText) tokens Example {
...
mode SomeMode {
pattern("cat") {
if(doCat) {
trigger ID=catText;
}
}
}
}
The above example uses two uses of supplied values. The first is for the if statement, and the
second is the text used in the token for the trigger statement.
Note that user variables cannot be used in the actual matching as the state machine
that does the matching is created at compile time, not run time.
Referencing variables (version 1.1)
As of version 1.1 of AustenX, variables referenced in lex expressions may or may not have a "$" at the start. This
is to ensure consistency of appearance with the PEG use of variables (without breaking version 1.0 code). So, for example, the following is also valid:
pattern("cat") {
if($doCat) {
trigger ID=$catText;
}
}
Complex types
Where the user supplied variables comes most into their own is with regards to complex types, .
Complex types are defined in Austen through the "interface" mechanism (see the section on user interface definition for how
to define a interface). If a interface has been defined, and a variable supplied of that interface type,
then the methods of that interface can be accessed in the action sections of the lex parsing. This
is very useful as it provides a way to add a lot of functionality that may otherwise be
missing from Austen, and allows the flexibility lost by making Austen language independent.
User interfaces describe types with methods that can be called, so variables of user interface
type can have their methods accessed in the action blocks. Again, the syntax follows Java. So,
for example, consider the following interface and usuage:
interface Happy {
boolean flipCoin();
int convertHex(string base);
int add(int first, int second);
void notifyOfCat();
}
lex Complex(Happy h) tokens Example {
...
HEX_DIGIT = {{'0'-'9'}|{'a'-'f'}|{'A'-'F'}};
mode SomeMode {
pattern("cat") {
h.notifyOfCat();
if(h.flipCoin()) {
trigger ID;
}
}
pattern("0x" $start HEX_DIGIT+ $+end) {
trigger NUMBER=h.convertHex(base: range(low: $start, high:$end));
}
}
}
The above example illustrates two possible uses for complex types. We shall break it
down by first looking at the components used. First, an interface "Happy"
is defined. The lexical analysiser "Complex" is defined with one parameter, "h", being of type
"Happy". From a code generated point of view. This means, a "HappyUser" interface will be generated:
public interface HappyUser {
public boolean flipCoin();
public int convertHex(String base);
public int add(int first, int second);
public void notifyOfCat();
}
... and the created lex parser class will have a constructor like so:
public class ComplexLexParser {
...
public ComplexLexParser(HappyUser hValue) {
...
}
...
}
So, in order to use the ComplexLexParser, the user programmer must supply a an object that
implements the "HappyUser" interface.
Now, during the lex parsing, the generated parser code will make calls to the HappyUser instance
provided, enabling interaction with user code during the parsing process. Thus, the "flipCoin"
method will be called whenever "cat" is matched (and parsing will act accordingly), and "convertHex"
is called (apparently to convert hexadecimal numbers into integer values).
The method "notifyOfCat()" is called not as an expression, but as a command. Other than that, it
functions the same as other method uses.
Passing argument values
The only thing to note is the syntax for passing argument values to methods that require them.
This follows the approach taken for internal functions (eg "range"), where parameters are referenced
by name (so order does not matter). This can either be in the form "parameterName" "=" "expression", or
in the form "parameterName" ":" "expression". Unnamed values are not currently accepted.
Note also that the values passed can be reasonably complex expressions, including other calls to
methods/functions. So the following is valid:
pattern("4x" $start HEX_DIGIT+ $+end) {
trigger NUMBER=h.add(second: 4, first: h.convertHex(base: range(low: $start, high:$end)));
}
(Note, that the "add" method is used above because no "+" functionality current exists within
AustenX. There is only so far down the "making it a programming language" road I feel I need to
go at the moment, when the rare uses for such functionality can be covered by the complex type and
method approach).
System variables
From version 1.1 there are a few extra supplied system variables (which will be replaced by
user variables of the same name). They just allow access to some of the data stored during
the parsing process. They are as follows:
- line, which returns the line number of the next token to be triggered (type int)
- char, which returns the character number of the next token to be triggered (type int)
- length, which returns the length of the current matched string full text (should
only be accessed during pattern match action blocks, not the start/end ones) (type int)
- text, which returns the full text current matched string (should
only be accessed during pattern match action blocks, not the start/end ones) (type string).
Variables and pattern libraries
Pattern libraries can also include system variables. To do this, the context in which that library is
used must provide the values for each variable. So, for example, one could define a library as such:
pattern library Cat(string catText, int number) tokens Example {
pattern ( "cat" ) {
trigger NUMBER=number;
print("Cat:", catText);
}
}
To use the library, values for the variables must be passed in the same named way that arguments are passed
to method calls. So for example:
lex MyCatUser tokens Example uses GeneralDefs {
...
mode normal {
...
pattern ( "whale" ) { trigger WHALE_KEYWORD & ID; }
library Cat(catText: "MEOW", number: 4);
...
}
}
Lazy evaluation
An important thing to note is that the values passed are lazily evaluated, so if a method call is passed as a value,
that method is called each time the library uses that variable. So for example:
interface Dog {
string dogText(int x);
int dogNumber(string x);
}
lex MyCatUser(Dog dog) tokens Example uses GeneralDefs {
...
mode normal {
...
library Cat(catText: dog.dogText(x: 5), number: dog.dogNumber(x: "woof"));
...
}
}
In this case, each time "cat" is matched (by the Cat library) a "NUMBER" token is triggered, with the
value of parameter "number", except this is provided by the evaluation of "dog.dogNumber(x: "woof")", and
this evaluation is done for each and every time "cat" is matched. Which means, if "cat" is matched 10 times
in a parse, then the "dogNumber()" method of the supplied "Dog" instance will be called 10 times.
Parsing Expression Grammars(PEGS)
Lexical analysis is cool and all, but every dog and their octopus can do that, and probably better
than Austen. Where Austen aims to gain "oos" and "aas" is with its gramatical parsing through
Parsing Expression Grammar, or PEG, based parsing. First though, before we go into how to write an Austen PEG parser, a explanation of PEG parsing is required,
and the ideas of recursive descent that underpin it.
What is a PEG Parser?
Parsing Expression Grammars (Ford) are a way of describing of understanding the contents of a file (or rather a set of tokens).
It is based on a framework of describing how to read information, in a "greedy" way, rather than the often used
approaches which are based on a language rooted in text generation (eg, context free grammars). This makes a
lot more sense to me, which is why I think PEGS are cool.
Having said that, if you have used a generative based parser before (like Bison/YACC, or something similar)
than the syntax of PEG rules will seem very familiar; they only differ in subtle, but important ways. There is
also a certain similarity with the NFA based lexical analysis, and other regular expression languages, but
again, things are a little different.
The most basic expressions
A PEG is a set of parsing rules. A rule is a set of expressions (parsing expressions if you will). The most
basic of the expressions is a single character (for most PEG parsers), or in Austen's case, a token. So a rule might be:
HappyRule := ID
That's not Austen syntax (I'm just harking back to the good old days of Pascal),
but basically it says that HappyRule matches the token ID. Obviously
this is not very useful, so the next expression is the "series" expression, which is
just things being listed in match order. So, for example:
ZebraRule := ID NUMBER STRING
In this case, ZebraRule is matched when an ID token followed by a NUMBERfollowed by
a STRING is encountered. The next expression type is similar to the token, and is just another rule. So for
example, we could have:
ZebraRule := HappyRule NUMBER STRING
This version of ZebraRule functions to match the same input as
the previous version, but does so by referencing HappyRule. HappyRule
has to match for ZebraRule to match.
Now we have described the two basic expression types, we can talk about
how the parser algorithm works.
Greediness and Recursive Descent
The goal of the parser is to
find a rule that "comsumes" the input starting from a particular token. If we
imagine a cursor sitting at particular token, a rule expression consumes
zero or more tokens of input, leaving the cursor moved to after the last
token consumed. A rule is said to succeed if all the expressions of
that rule successfull consume input. If any expression fails to match the
input (and cannot consume it), than no input for that rule is consumed, and
the cursor returns to the point when the rule was first tested.
This process of consumption can be converted in a straight forward
way to computer code. For example, HappyRule might translate as:
function HappyRule() {
markCursor();
//consumeX() is a set of functions for each token X that
// return true if they consume the token at the current input,
// false otherwise.
if(!consumeID()) {
//Set cursot back to start
backToMark();
return false;
}
//Successful, so remove mark for got form
removeLastMark();
return true;
}
Given the definition of HappyRule, then ZebraRule might
follow as:
function ZebraRule() {
markCursor();
if(!HappyRule()) { backToMark(); return false; }
if(!consumeNumber()) { backToMark(); return false; }
if(!consumeString()) { backToMark(); return false; }
//Successful, so remove mark for got form
removeLastMark();
return true;
}
This is a nice translation from a parser rule to actual code, and
easy to understand (it roughly follows what happens within the code generated by AustenX). Note
the use of backtracking the cursor when a consumption fails.
Also of note is the call to HappyRule from within ZebraRule, and this is where things get interesting.
Repeated and possible patterns.
In the previous examples we have just matched either tokens, or other patterns. Like the lexical analysis there
are other operators available. Some of these are similar to regular expressions, such as the "*", "+", and "?" operators,
which perform the zero or more, one or more, or maybe, operations. So for example, a possible PEG pattern might be:
Strange :=
NUMBER PLUS_SYMBOL+ NUMBER?
The above matches a NUMBER followed by one or more "+" tokens, followed, possibly by another number. Where
this differs from the regular expressions is in the greedy nature of PEGs. The following example, which groups
items together as well, illustrates the consequences of the greedy consumption of input:
Strange2 :=
NUMBER PLUS_SYMBOL+ { PLUS_SYMBOL NUMBER } ?
The example Strange2 is similar to Strange, but after matching one or more "+" tokens, there
is the possibility of matching a "+" followed by a number (the "{" and "}" make a block, that the "?" operator
matches on as a whole). The problem is, the "PLUS_SYMBOL+" will consume all the "+" tokens, upto the first instance
of a token that is not a "+", so there is no "+" available for the last part of the pattern to match. If we
rewrite it one more time, we see the greedy nature of PEGs means some patterns cannot be matched:
Strange3 :=
NUMBER PLUS_SYMBOL+ PLUS_SYMBOL NUMBER
In the previous example, Strange3 would never match anything, as the second PLUS_SYMBOL must
be matched, but no appropriate input will be available for consumption after the "PLUS_SYMBOL+" has finished
doing its thing.
The "or"/"choice" operator
A core operator, and one where the greedy element of PEG parsing is so important, and also
one where some of the the inovations present in Austen are to be found, are with the "or" operator.
The "or" operator matches one of a set of possible sub patterns.
Traditionally, with PEG parsers, this is marked by using a "/" symbol, in place of the "|" symbol
used with other parsing approaches. This alteration in syntax is to emphasise the greedy nature
of the "or" operation, where the sub patterns are attempted, and the first one that successfully
consumes input is used, and no further options are tried. This is different to say the case
with NFA regular expressions used in Austen's Lex blocks, where the longest match is used (or rather
potentially used, if that gives the longest match for the overall pattern). I think this is
pointless, so I will use the traditional vertical bar, "|" (and AustenX uses the "/" for
another purpose). So, for example:
IdPlus := ID PLUS_SYMBOL
Options :=
IdPlus | { NUMBER PLUS_SYMBOL} | ID+
In this case, the pattern "Options" can either be matched by the pattern "IdPlus", or a number token followed
by a "+" token, or one or more "ID" tokens. It cannot be matched by more than one option, and the options
are tried in order. First, the pattern "IdPlus" is checked to see if successfully consumes input. If so,
then "Options" succeeds (and the cursor moves on), or else the cursor returns to the starting token (for this
resolution), and the next option is tried (the number and the "+"). If no option succeeds, than the pattern "Options"
fails.
Lookahead, non-consuming, operators
The next set of operators that PEGs use are a bit less common in the world of parsing, as they involve
"looking ahead" in the input, but not actually consuming input.
Followed by, "&"
The first is the followed by operator, marked
with an "&" before the elements to check (not after like with "+", "*", "?"). This operator checks that
the input following the current cursor position matches a set of pattern elements. So for example:
FollowedBy := ID & PLUS_SYMBOL
In this case, the pattern "FollowedBy" is successful if it consumes first an "ID" token, and then is followed by
a "+". Because the followed by "&" operator does not consume output, the cursor will be left after the "ID" (at
the point of the "+" token.
Not followed by, "!"
A similar operator, that is used a very similar fashion to "&" is the not followed by operator,
which again, does not consume any input, but succeeds if it fails to match the specified pattern. It is used
to check if something is not followed by a certain pattern. So for example:
NotFollowedBy := ID ! PLUS_SYMBOL
In this case, the pattern "NotFollowedBy" is successful if it consumes first an "ID" token, and then is followed by
anything but a "+" token. Because the followed by "!" operator does not consume output, the cursor will be left after the "ID" (at
the point of the "!" token. One can combine operators of course, so the following is valid too:
NotFollowedByMulti := ID ! { PLUS_SYMBOL | STAR_SYMBOL }
In this case, the pattern "NotFollowedBy" is successful if it consumes first an "ID" token, and then is followed by
anything but a "+" token, or a "*". (The grouping "{}" braces are not actually needed because of the
precedence of the "|".
| Expression | Meaning |
| id | A reference to another pattern, or a token (tokens by convention are all-caps,
patterns are CamelCaps. |
| e1 e2 | Sequential match: first expression e1 is consumed, then expressione2. |
| { e1 e2 } | Block match: consume expressions within block, but treat as an atomic block for further operations. |
| e? | Attempt to consume expression e consumed, do not fail pattern if unsuccessful. |
| e+ | Consume at least one expression e, and than as many more as possible. |
| e* | Consume as many of expression e as possible, or none. Equivalent to e+? |
| e1 | e2 | Consume either e1 or e2, trying e1 first (if successful,
e2 never tested). |
| &e | Is a successful match in a pattern if expression e is able to
be consumed from the current position in the input. Does not consume any input. |
| !e | Is a successful match in a pattern if expression e is not able to
be consumed from the current position in the input. Does not consume any input. |
Memorisation taster.
In the previous example, of a function that consumes input, there is a call to another function that consumes input. This raises
a couple of issues. The first is efficiency. It may well be possible that a particular rule may be invoked multiple times
at a particular cursor position, as different rules are applied (for example, consider an "or" operation), yet each call
will yield the same result, with the same computations. Is it possible to avoid this inefficiency? The answer is, yes, using a
dynamic programming solution, where a table rule resolutions at particular sites is stored, and this will be elaborated on later.
For the most part, the user of AustenX does not have to really understand the memorisation (if used), except that memorisation
is a tradeoff of memory for faster computation (potentially).
Recurssion
Return to the issues the example presents, there is a second one and that comes from recursive calls. It is, and should be, perfectly
sensible to have rules that refer to them selves. The prototypical example of this is with "expressions" in languages. A basic example is
the follow:
Expression :=
{ Expression PLUS_SYMBOL Expression } |
NUMBER
By this, Expression is a rule which consumes either the series Expression, followed by the PLUS_SYMBOL ("+"),
followed by another expression, or, just a simple INTEGER token is consumed. Remember the greedy nature of "or", if the first option
succeeds, the second is not tested.
Now, here is a problem if the recursion is "left". This can be seen if we look at what code might be equivalent to this rule:
function ExpressionRuleOptionOne() {
markCursor();
if(!ExpressionRule()) { backToMark(); return false; }
if(!consumePlusSymbol()) { backToMark(); return false; }
if(!ExpressionRule()) { backToMark(); return false; }
removeLastMark();
return true;
}
function ExpressionRuleOptionTwo() {
markCursor();
if(!consumePlusNumber()) { backToMark(); return false; }
removeLastMark();
return true;
}
function ExpressionRule() {
if(ExpressionRuleOptionOne()) { return true; }
if(ExpressionRuleOptionTwo()) { return true; }
return false;
}
This is a slighly more involved piece of code, and not quite how AustenX generates things, but you should get the idea. The
astute reader (that's you) will pick out though that there is a slight "quirk" in the code. ExpressionRule calls
ExpressionRuleOptionOne, without consuming input, and ExpressionRuleOptionOne calls ExpressionRule,
again without consuming any input. The result of this is that each function will continually keep calling each other,
and we are staring into the abyss of infinite recurssion. Note that this problem does not occur if the recurssion is
not "left" (that is, occurs after at least one token of input has been consumed). No left recurssion seems such a shame, because that is a nice way to write
a grammar, and it would be sad not to be able to write such rules. Thankfully, a number of similar solutions to the
problem have been found, and AustenX uses such a solution, so such recursions are perfectly acceptable. Unfortunately, the solutions have
quirks though regarding precedance, and do not always result in intuitive results. Thankfully again, AustenX is a bit cool, and
sorts that out too. Further details on that will have to wait to later in this document though.
Writing an Austen PEG parser
The above should have given the reader a brief overview of how PEG based parsers work. Don't worry if you didn't, as things
we will go over the idea again, but this time within the particular way Austen works.
There are more features that AustenX allows, and we will examine
those with greater detail as we proceed. First, we begin with an explanation of the basic syntax.
The PEG block
The PEG block is defined in a similar way to the LEX block. A basic example would be:
peg ExamplePEG tokens Example{
...
}
In this case, a PEG block named "ExamplePEG" is being defined, that uses the "Example" tokens (as the LEX
block parsed for). The tokens are the name of the tokens block, not the lex block. One could write
their own lexical analyser; the PEG parser does not care how the tokens were derived, just what form they take.
The peg keyword can be replaced with packrat, as historically that is what was used, but then
I realised that the parser has moved beyond being specifidcally a packrat parser, and may infact not use packrat
parsing at all (if no memorisation is used).
Inside the PEG block things get interesting. The typically element within the block is the pattern
declaration. Pattern declarations come in two forms: the basic pattern, and the option pattern. Both equate with
a general PEG pattern, but the option pattern has a specific set of options (choice options - like with the "|"
operator), that have specific meaning in how the parsing is performed, and what code is produced as a result.
Basic patterns
Both basic and option patterns are marked with the pattern keyword. A basic pattern is of the form:
pattern Name ( PatternElements );
That is, first the pattern keyword, then the name of the pattern (in normal identifier form), then
a round bracket "(", then the pattern elements then a closeing bracket ")", then an optional semi-colon (I try to
keep semi-colons optional, even though I like using them, as an example of the awesomeness of PEG parsing, and
the general lack of need for such things).
Option patterns
An option pattern is of the form:
pattern Name {
OptionOne ( PatternElements1 );
OptionTwo ( PatternElements2 );
...
OptionN ( PatternElements3 );
}
That is, first the pattern keyword, then the name of the pattern (in normal identifier form), then
a curly bracket "{", then the set of different options, followed by a closeing bracket "}". The individual options
(of which there can be one or more) are presented as for the the basic patterns, without the extra pattern keywords.
Again, the ending semi-colon in each case is optional.
An option pattern will match whatever option matches first. That is, the first option, in order presented,
that successfully consumes input, will be the pattern that matches overall. But, before more explanation can
be given on that, we should first attend to what the "PatternElements" are.
The Basic Pattern Elements
The pattern elements follow a similar form to the PEG language described previously. The most atomic element is the
pattern or token reference, which is just the name of the thing being referenced. If there is a pattern with the same
name as a token, the pattern will be detected first. Elements can be listed sequentially, such that each element is in
turn tested to consume input so the following is valid:
pattern Example2 {
Number ( NUMBER );
ID ( ID );
}
pattern Example1( ID STRING Example2 ID Example2 );
In the above example, the pattern example attempts to consume an ID token, then a STRING token then whatever
Example2 matches (in this case, either a NUMBER or and ID), another ID, and another Example2 (which may be different
to what was consumed by the first Example2 reference.
The choice operator "|", the zero or more ("*"), one or more ("+"), and maybe operators ("?"), as well as the
followed-by, and not-followed-by lookahead operators ("&", and "!" respectively), work as described in the section
on general PEGS. Elements can also be grouped as before by enclosing the elements in curly brackets ("{ }"). Thus, the following
is a valid Austen rule:
pattern Example3 ( Example1? Example2* STRING+ !ID Example1 | Example2 { STRING ID Example2 }+ );
Divided elements
The previous section described the direct translation of normal PEG expressions to Austen pattern definitions. There are a number of
further adaptions to the basic PEG structure that Austen uses, but most of those are non-trivial extensions, and are described later. One that is a relatively
simple, and acts as "syntactic sugar" (though it is compiled differently), is the divider operator, marked by "/", which is used in normal
PEGs to show the greedy choice option (which Austen uses the "|" for). The divider operator is useful for when one has
wishes to parse a list of items, such as one would do with the zero-or-more ("*"), or one-or-more ("+") opertors, but
wants the list to be seperated by some other items. In English, the obvious example is a normal list being seperated by commas
(cat, dog, moose), which is commonly transfered across to programming languages for listing items or parameters (a = [1,2,3]). Of note is
that the comma divides the items; it is not valid to have another comma after the last item, or before the first. Using
basic PEG grammar we could write an Austen pattern as such (hopefully the unmentioned named elements are obvious by
their name):
pattern FunctionCall ( ID LEFT_ROUND { Expression { COMMA Expression } * }? RIGHT_ROUND );
This pattern matches a "function call", which is of the form: function name, followed by a left round bracket,
followed by zero or more parameter values (from general expressions), seperated by a comma, followed by a right
round bracket. That is, a function call common to many languages. This form a little convolted, and not very easy to read.
The divider operator can be used to state the same form as follows:
pattern FunctionCall ( ID LEFT_ROUND Expression* / COMMA RIGHT_ROUND );
The "Expression* / COMMA" bit can be read as "zero or more Expressions, divided by a COMMA". Alternatively, if for some reason
you want one or more elements divided by something you could use something like the following:
pattern FunctionCallOdd ( ID LEFT_ROUND Expression+ / COMMA RIGHT_ROUND );
The divider does not have to be a single token, it can be any general element, so the following is valid too:
pattern FunctionCallOdder ( ID LEFT_ROUND Expression+ / { COMMA { LEFT_CURLY _RIGHT_CURLY }* / STRING }? RIGHT_ROUND );
If that does not make sense to you, it means one or more expressions divided, possibly, by a comma followed by zero or more "{}" couples divided
by a String token (eg "cat")). Also note, that legacy versions of Austen files (if you are looking through source
written by me), use the simpler version of the divider where the zero-or-more, or one-or-more bit is not present, such as:
pattern FunctionCallOdd ( ID LEFT_ROUND Expression / COMMA RIGHT_ROUND );
This form is the same functionality as for the one-or-more version, so you may see the following written, as
the older way to write "zero-or-more divided-by":
pattern FunctionCall ( ID LEFT_ROUND { Expression / COMMA} ? RIGHT_ROUND );
I expect this form to remain acceptable by Austen for the forseeable future, but it is deprecated, so do not
use it.
A Note on Memorisation
The reader may remember that Austen is, at the moment, essentially a packrat parser algoritm, and that by default pattern evaluations are stored. This can be altered in two ways.
The first is the "pattern*" notation, where "*" is placed after the pattern keyword. This indicates that memorisation should not be used
for that particular rule/pattern. For example:
pattern* FunctionCall ( ID LEFT_ROUND { Expression / COMMA} ? RIGHT_ROUND );
This works as the previous definition (and to the user is has not tangible effect, except to use less memory).
The other method is to specify avoiding memorisation altogether, and this is done again via a "*" notation, this time though in the
pegs definition itself, after the peg keyword. So, for example:
peg* ExamplePEG tokens Example{
...
}
The above would produce a parser that has the same functional behaviour as the memorisation one, but by default none of the
patternss/rules are memorised. In this case though it is possible to select memorisation by using the "pattern*" notation.
Notation recap
By default, to inhibit memorisation, use the "pattern*" notation. To inhibit memorisation by default, use the "peg*" notiation.
If using the "peg*" notation, use the "pattern*" notiation to enable memorisation for a particular pattern.
Space usage with and without memorisation
The difference between using memorisation and not is in the amount of memory used, obviously. With memorisation, the memory usage
is proportional to the number of tokens (or number of possible positions for a rule). Without memorisation, it is the depth of pattern
matches that matter. So, if one pattern matches another, and that second pattern just matches tokens, then that is a depth of 2. If the
second matched pattern matches another layer, that is a depth of 3. If a left-recursive pattern matches itself, that increases the depth
by 1. In general, this depth is quite low. If I have a function call with a function call for a parameter, inside a method, inside a class,
that will probably only be a depth of around 4 or 5.
On the other hand, memorisation avoids the repeated evaluation of a rule starting at a particular token position. Without
memorisation a rule may experience repeated evaluations at a particular site (there is a little bit of code to avoid this if possible though).
You can use the statistics provided by the BuildStats object to evaluate which rules may need memorisation.
From anecdotal use, I would say that memorisation is seldom needed, and even when it might help (often with expressions), the benefit is
small. Maybe in a future version of Austen memorisation will be turned off by default.
Connecting Austen with code
The previous section described the basic usage of the PEG parser of Austen, but did not go into details on any
significant special features of Austen. Before we reach that point it is important to first describe who a
parser definition links with the code created by Austen.
In the following, when the "user" is refered to, I mean the programmer who is using the code generated by
Austen.
Instructing the user
The most important thing to understand about the current version of Austen is that it generates code
to "instruct" the user based on the parse of the input. That is, it does not produce a parse tree for
the user to traverse.
Austen, in its parsing of input, does build up an internal parse tree of sorts. This parse tree does not
store all the information of the parse, but rather, only what the user cares about. Once this internal
parse data is completed, the user code is then "instructed" to build a user parse tree. This instruction occurs
through a specific interface that is built by the code generation process.
Making something relevant
Before we quite get into what the generated code looks like, there is the matter of marking parse information
as interesting. We will also quickly introduce the idea of "top-level", and "sub-level" elements.
Tagging elements
To mark something as interesting we "tag" it with a name. This is quite straightforward, and just involes
typing a colon, ":", after the named element in our patter, and then the name of the tag. So for example, we
might do:
pattern Addition( ID:number PLUS_SYMBOL Addition:nextBit );
In the above example, two elements are tagged, and one is not (the "+" token). The first item tagged is the
ID token, and the second thing tagged is a reference to an Addition pattern input consumption, which
is being tagged as "nextBit". My convention is to use "camelCaps" for tag names. As will be seen in the code
generation section, "CamelCaps" names will not affect the generated code, but I personally have a preference for
the lowercase version (they are sort of like variables).
As an asside, the previous example also uses a right-recursive "call" to itself, and will fail on any input,
as there is no non-right-recursive option. A more useful version would be:
pattern Addition {
Plus ( ID:number PLUS_SYMBOL Addition:nextBit );
Base ( ID:number );
}
Top-level, sub-level
I will introduce this concept now, even though its relevance may not be apparent yet, as it will ease explanation later.
Elements can be either "top-level" or "sub-level", and these terms relate to how soon parse information can be
seen as certain. As a way to introduce this distinction, consider the following exampel:
pattern Main ( ID:firstName OtherStuff:otherBits* / COMMA ID:secondName );
Now consider the parse has parsed some text, and is talking to you, the user's program. Austen's parser says it
parsed the text as pattern Main. Now this means, that there are a bunch of OtherStuff items in there (or
none), but from knowing that Main has been matched, it is not immediately obvious how many OtherStuff items
there are. But, know that Main has been matched does mean straight away that there must be an ID token
at the beginning (tagged "firstName"), and an ID token at the end (tagged "secondName"). It is these
two "immediate" elements that are called "top-level", as they can be identified as soon as notification of the Main
pattern match is given.
A bit more clarification about top-level elements is that they are always named items, and they are almost always tokens
only. The reason for all this will become more clear once the actual code generation is described. It suffices to say
that all other elements are "sub-level", so for example:
pattern Sub1 ( ID:sub* );
pattern Sub2 ( { ID:sub } );
pattern Top ( ID:top );
In the above example, and in the first cases, the ID token tagged as "sub", is sub-level, while
the ID tagged is top-level. An important thing to note is the use of the blocking operator (the "{...}"),
to turn a top-level token into a sub-level one.
A Pattern Peer
In Austen, the instruction is done to "Peers". Peers are user classes that are defined by interfaces. For Java, if the
current output (as defined by the "output" keyword, see the second on basic usage), is "x.y", then the peer interfaces
will appear in the package/folder "x.y.peg.base". Any partiuclar pattern may have a Peer interface associated
with it. If a pattern has only top-level tagged elements, then (in most cases) it will not have an associated peer, but
if it does have at least one sub-level tagged element, then it will have an associated Peer interface.
If a pattern has the name "X", and has sub-level tagged elements, there will be generated a peer interface with a
name formed by its name followed by Peer, so in the case of pattern X, that would XPeer. How a Peer looks depends
on whether the pattern is basic, or an option pattern (see above). For now, we will discuss the simpler
case of the basic pattern.
Sub-level tokens
If there is a sub-level tagged token in the pattern then, in the associated Peer interface (assuming for
now a basic pattern), there will appear a method of the form
public void addTokenTag(Type value) ;
So, for example, consider the pattern as follows:
pattern OneSub ( LEFT_ROUND NUMBER:number* / COMMA RIGHT_ROUND );
This pattern matches something of the form "( 1,2,3,4,5 )", for example. There are multiple things
that may be matched as a NUMBER token, and we have tagged that match as "number" (to make things
a bit more exotic). This would produce a Peer interface with the following form:
package x.y.peg.base;
public interface OneSubPatternPeer {
public void addNumber(int value);
public void end();
}
(The Peer interface for a pattern, at least the simple ones, is the pattern's name with "PatternPeer" appended)
Untagged tokens (or top-level tokens that are tagged), do not appear in the Peer interface.
The end() Method
You may notice there is an additional method prototype in there - the "end" method. This is called, when
all other parts of the pattern have been "notified" to the Peer. In future versions this will be optional, at
the moment users must implement this method, even if they don't care.
The Token Value
The token value, the value supplied in the "add" method, comes from the token itself, and is dictated by
the type of the token (from way back in the tokens definition). If the type of the token is void, there
is not value given. Curently the valid types are at least double, boolean, int, and String.
The Token Line/Character
It is also possible to get notified of the token's position in the text file. To do this, use "@" before the name
of the token in the pattern definition. So for example,
pattern OneSubTokenWithPos ( LEFT_ROUND @NUMBER:number* / COMMA RIGHT_ROUND );
would generate:
package x.y.peg.base;
public interface OneSubTokenWithPosPatternPeer {
public void addNumber(int value, int line, int character);
public void end();
}
This works even if the token type is void, but you must tag the token (no value is included though); it does not work, obviously, if
the token is untagged.
Multiple Same Tags
Just a quick note about tagging. You may tag more than one use of a token (or a pattern) with the same
tag. This results in only one method showing up in the Peer. Consider rewriting pattern OneSub as follows:
pattern OneSub ( NUMBER:number+ ID { NUMBER:number NUMBER:number }? );
If the above pattern is compiled, the result OneSubPatternPeer will be the same as before, even though the semantics
have changed somewhat.
Sub-level patterns
Tokens are easy while tagged sub-level patterns (which usually means all tagged patterns) are more complex.
This is also where the top-level/sub-level distinction starts to come together. You may have been wondering about
top-level tagged tokens? Well, they show up with how the sub-patterns are used. First though, we will look at the most basic case,
where the pattern being added has no top-level tokens.
For example consider:
pattern OneSubTokenWithPos ( LEFT_ROUND @NUMBER:number* / COMMA RIGHT_ROUND );
pattern OneSubRule ( LEFT_SQUARE OneSubTokenWithPos:subRule / COMMA RIGHT_SQUARE );
would generate, first the OneSubTokenWithPosPatternPeer interface described above, as well as the following
interface:
package x.y.peg.base;
public interface OneSubRulePatternPeer {
public OneSubTokenWithPosPatternPeer addSubRule();
public void end();
}
The way the "instruction" works is that while instructing a user class implementing the OneSubRulePatternPeer interface,
for each sub rule of form OneSubTokenWithPos, the addSubRule() method is called.
Each "child" sub rule is dealt with completely, before the next child of the parent is processed (and
end() is called when all is done). So for example, consider the following input:
[(2,3),(4)]
Assuming the Austen instructor has obtained a reference to a OneSubRulePatternPeer instance (from a
another Peer, or from the "root", as will be described later), the call pattern proceeds as follows.
First, the addSubRule() is called on the OneSubRulePatternPeer implementing user class. This is
essentially asking the user code for a OneSubTokenWithPosPatternPeer instance, that can then be further instructed.
On returning such an instance OneSubTokenWithPosPatternPeer by the user, for that instance, the addNumber()
is called twice, first for "2", and then for "3". After this, the end() method of OneSubTokenWithPosPatternPeer instance
is called, and then the instructor returns to the parent OneSubRulePatternPeer instance, to call the addSubRule() method once more.
On the returned OneSubTokenWithPosPatternPeer instance (which could be the same one returned previously),
the addNumber() method is called one more time, with the value "4", and then end(), and then
the end() of the original OneSubRulePatternPeer parent instance is called.
To summarise, the pattern can be seen in this poorly structured diagram (with the red numbers representing call
order):
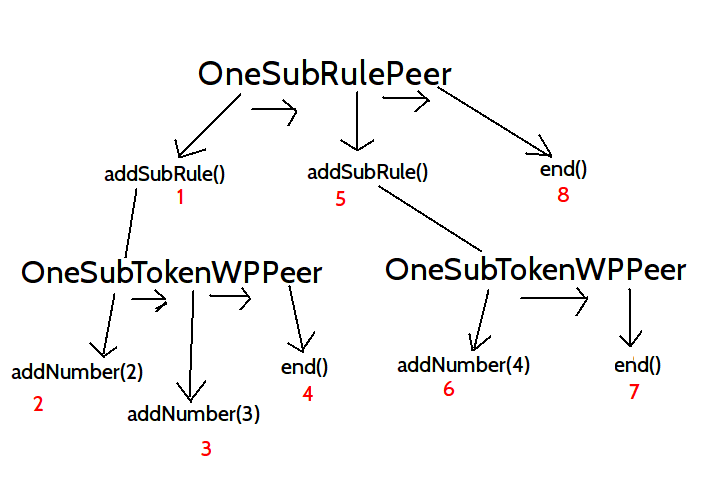
Sub-level patterns with top-level tokens
Now that we have the basics out of the way, the next step is how the top-level tokens fit in. Until now, it
has not been possible to explain this until the concept of the sub-level rules had been explained. The
top-level tokens come into play with the invocations of the sub-rules during the instructing process. Since
the top-level tokens are fixed they can be provided when the sub-rule Peer is requested. So consider the following
rules:
pattern MixedTokens ( ID:name LEFT_ROUND NUMBER:number* / COMMA RIGHT_ROUND );
pattern OneSubRuleWithTopLevel ( LEFT_SQUARE MixedTokens:subRule / COMMA RIGHT_SQUARE );
Now this produces two interfaces for the user to implement, as follows:
package x.y.peg.base;
public interface MixedTokens {
public void addNumber(int value);
}
...
package x.y.peg.base;
public interface OneSubRuleWithTopLevelPatternPeer {
public MixedTokens addSubRule(String name);
public void end();
}
The resulting interfaces would be very similar to the previous example, except there is now a
top-level token in the form of the ID token (of type String) in the MixedTokens pattern.
This is a top-level token, as it is only matched once, and must be matched, and does not occur within any
sub block. Because of this, and because the token is tagged "name", it can be supplied to the
user when requesting the MixedTokens peer.
Halting parse instruction
If the parser requests a "PatternPeer" for a sub-rule reference, and the user does not want to continue
with parsing for that particular sub-rule, the user only has to return null, and the parser will
move on (a null pointer exception is not generated).
Top-level tokens with position
If position markers are requested for a top-level token (with the "@" symbol), they are supplied with
the top-level token value. For example, changing the above:
pattern MixedTokens ( @ID:name LEFT_ROUND NUMBER:number* / COMMA RIGHT_ROUND );
pattern OneSubRuleWithTopLevel ( LEFT_SQUARE MixedTokens:subRule / COMMA RIGHT_SQUARE );
Will produce the following, as follows:
package x.y.peg.base;
public interface MixedTokens {
public void addNumber(int value);
}
...
package x.y.peg.base;
package munky.austenx.peg.library;
public interface OneSubRuleWithTopLevelPatternPeer {
public MixedTokens addSubRule(String name, int nameCharacterNumber, int nameLineNumber);
public void end();
}
If the token has no value, and is of the type void, then it is ignored at the top-level, unless position information is requested, in
which case the position information is supplied. For example:
pattern MixedTokens ( @LEFT_ROUND:left NUMBER:number* / COMMA RIGHT_ROUND:right );
pattern OneSubRuleWithTopLevel ( LEFT_SQUARE MixedTokens:subRule / COMMA RIGHT_SQUARE );
Will produce the following, as follows:
package x.y.peg.base;
public interface MixedTokensPatternPeer {
public void addNumber(int value);
}
...
package x.y.peg.base;
public interface OneSubRuleWithTopLevelPatternPeer {
public MixedTokens addSubRule(int leftCharacterNumber, int leftLineNumber,int rightCharacterNumber, int rightLineNumber);
public void end();
}
If there are only top-level tokens
One last point before we move on to more complex sub-rules (one with multiple options), a note needs to
be made when the sub rule is simpler. That is, if a pattern used only has top-level tokens, and no sub-tokens
or sub-rules. So for example, consider the following:
pattern TopTokens ( ID:name );
pattern OneSubRuleWithTopLevelB ( LEFT_SQUARE TopTokens:subRule / COMMA RIGHT_SQUARE );
Now this produces one interface for the user to implement, as follows:
package x.y.peg.base;
public interface OneSubRuleWithTopLevelBPatternPeer {
public void addSubRule(String name);
public void end();
}
As there is no need for a user Peer for the TopTokens rule, none is created, or requested. This
occurs when there are no tagged sub-level tokens or rule references. If there are no tagged
top-level tokens there will be no parameters.
Connecting Austen with code, part 2
Now the basics of how the user interacts with the generated parser have been discussed, the more
complex issues must be turned to. The most important is what happens when a pattern is a multiple option
one. This is more complex in a number of ways than with the single option case. Other issues deal with
defering the instruction to a later, and how the process is initiated in the first place (which we'll leave to
the next section).
Multi-option patterns
There are a two basic ways of dealing with multi-option patterns. The first, and default, way is what I
call the direct way, the second is the indirect way, though I ponder if that should be the other
way round. Either way just affects the code generated, and not the actual performance of the parser
Direct sub-rules
The direct method is specified with no extra language features to what would be used with single-option rules.
So, one may use the following two patterns:
pattern Multi {
First ( @ID:id );
Second ( NUMBER:value+ );
}
pattern Main ( Multi:sub / COMMA );
In this case the second pattern specifies a series of one or more matches of the Multi pattern,
seperated by commas. The Multi is a multi-option pattern, with the first matching an ID,
the second matching one or more of the NUMBER tokens.
The first difference when compiling, is that a "PatternPeer" interface is not created for multi-option patterns,
but rather just a "Peer" one (so in this case, MultiPeer. The "Peer" interface in itself is not important; it
is just a holder for a number of other interfaces. For now, all that matters is that it contains the "PatternPeer"
interfaces for each option, or rather, for each option that has tagged sub-rules or sub-tokens. So with regard to
Multi, the produced MultiPeer class looks roughly like:
package x.y.peg.base;
public interface MultiPeer {
public static interface SecondPatternPeer {
public void end() ;
public void addValue(int value) ;
}
}
So, the point here, is there is a "PatternPeer" interface for the Second option, but not for First, because
that option has only a top-level token.
The next part is what happens in the "PatternPeer" for the Main pattern. This pattern is just a simple
one, so the form is nothing basically special, but the way the sub sub-rule is handled is different. Instead of
one method for the sub-rule, there is one for each option in that sub-rule. So, we get the following:
package x.y.peg.base;
public interface MultiPeer {
public void end() ;
public void addOptionFirstOfMultiForSub(java.lang.String id, int idLine, int idCharacter) ;
public MultiPeer.SecondPatternPeer addOptionSecondOfMultiForSub() ;
}
So, as can be seen, there is one method for each option, and each method is of a similar form as
for a single simple sub-rule, but the formed name is more complex. The naming takes the form addOptionXofYForZ, where X is the
option name, Y is the name of the pattern type, and Z is the tag name.
Indirect sub-rules
With "direct" sub-rules, there is one new method in the "parent" peer for each option. Often though, the
user may have one particular class that handles all particulars of a pattern, and implementing multiple
methods, just to pass them on to another class, can be a hassle. So, Austen enables another way of
interacting with the tagged sub-rules. This is the "indirect" method.
To specified that in the generated user code, the indirect method is required, the current syntax
specifies a "-" in front of the pattern reference. (I thought to change this, as I tend to use the
indirect form most often, but I am leaving things as they are). So, consider the following:
pattern Multi {
First ( @ID:id );
Second ( NUMBER:value+ );
}
pattern MainIndirect ( -Multi:sub / COMMA );
Now, the difference comes in the generated code. The MultiPeer interface is the same as
previously, except previously there was another interface not listed above: in particular, the Indirect
interface. So, the full MultiPeer class appears as:
package x.y.peg.base;
public final class MultiPeer {
public static interface Indirect {
public void createFirst(java.lang.String id, int idLine, int idCharacter) ;
public MultiPeer.SecondPatternPeer createSecond() ;
}
public static interface SecondPatternPeer {
public void end() ;
public void addValue(int value) ;
}
}
The MainIndirectPatterPeer differs from the previous MainPatterPeer by looking as follows:
package x.y.peg.base;
public interface MainIndirectPatternPeer {
public void end() ;
public MultiPeer.Indirect getMultiForSub() ;
}
Now the individual "add" methods for "sub" are gone, and in their place is a single "get" method (getMultiForSub()), which
remains the same even if pattern Multi has a change in the number of options. Now, instead of the
parser directly calling the appropriate "add" method, first an suitable Indirect peer is requested,
and then the created peer is instructed according to the parsed option. The Indirect always appears
even if the pattern is never used indirectly (I think).
Indirect simple sub-rules
If the pattern referenced is a simple one (that is, with no options), then the result is as for
the direct case, even if indirect style is selected.
Halting parse instruction 2
As with simple rules, parsing instruction can be halted for any particular pattern by returning null
when requested for a "Peer" (either indirect, or a direct option peer).
Deferred sub-rules
There is one last current way of specifying how a sub-rule reference is managed, and that is "deferring"
instruction. Given the instruction process occurs in one go by the instructing algorithm, this
may cause inconvenience if it may be better for part of the parse-tree to be examined at a later date, or
for the instruction to be done multiple times. The solution to such problems is to defer the parsing
with the "--" operator, which works like the indirect "-" operator. So, for example, consider the following:
pattern Multi {
First ( @ID:id );
Second ( NUMBER:value+ );
}
pattern MainDeferring ( --Multi:sub / COMMA );
Now, the following interface is generated for MainDeferringPatternPeer:
package x.y.peg.base;
public interface MainDeferringPatternPeer {
public void end() ;
public void setMultiForSub(DeferredMulti value) ;
}
So now, instead of "add", or "get" methods, a "set" method is used to instruct the user Peer.
In this case, instead of requesting a Peer from the user, the user is given an object which can be
used for requesting instruction at a later point. Looking at the DeferredMulti interface
(implemented by an object supplied by the instructor) we see:
package x.y.peg.base;
public interface DeferredMulti {
public void buildMulti(MultiPeer.Indirect target) ;
}
Now, the user can request parsing of the sub-rule at a later date by calling the buildMulti() method (passing
in an indirect peer, or something similar in the case of a simple pattern (I forget what - it's probably an
Indirect version or something, or I forgot to implement that). This method can be called multiple times.
Connecting Austen with code, part 3
Given the description of the peers from part 1 and 2, the last step in
the general code construction section, is how the parsing is started. How does
the user initiate the parse?
Specifying root patterns
The first thing to do is to include in the parser description an indication of
what patterns are "root" ones. That is, what patterns are to be tried when starting
parsing fresh. The way to do this is very straight forward &ldash; one just uses
the root keyword, at somepoint within the packrat definition..
For example:
packrat Test tokens ExampleTokens {
root File;
pattern File (
imports.Import:imports*
Statement:statement*;
);
...
}
So, in the above example, most of the details have been omited, but there is a definition
for the File pattern, and the use of the root keyword to specify File as a root
pattern (I had thought of placing the root declaration with a specific pattern - and maybe that
is actually allowed, or will be - I can't remember, but at the time, for some wise reason I supose,
I opted for a seperate root declaration).
Multiple patterns can be specified as root patterns (via multiple root declarations, and possibly
via a single declaration with multiple, comma-seperated, references).
RootBuilder classes
If a pattern is specified as a root pattern then a "RootBuilder" interface will be created. These interfaces
are regarded as specific to packrat parsers (for now), so appear in the "x.y.packrat.library" package (where "x.y" is the base package - note the "packrat.library" sub package, not "peg.library").
The "RootBuilder" class are formed by combining the pattern name, with "RootBuilderFor", ending with the packrat name.
So, the following is formed for the above(for packrat "Test"):
package x.y.packrat.library;
public interface FileRootBuilderForTest {
public FilePatternPeer buildFile() ;
}
As can be seen, this is where the first connection to a FilePatternPeer occurs./p>
The Packrat class
The access for point for the generated packrat parser is in the "Packrat" class (named by the packrat name, with
"Packrat" on the end). This is found in the "x.y.pakrat.library" package (with the "RootBuilders"). It takes
the form of roughtly (for the above Test packrat):
package x.y.packrat.library;
public class TestPackrat {
public static final org.ffd2.austenx.runtime.BuildStats quickAndSimpleBuild(
org.ffd2.solar.language.CharacterSource fileText,
ExampleLexParser parser,
FileRootBuilderForTest target,
org.ffd2.austenx.runtime.ParserErrorCatcher errorCatcher
) {
...
}
public static final org.ffd2.austenx.runtime.BuildStats quickBuildFile(
org.ffd2.solar.language.CharacterSource fileText,
ExampleLexParser parser,
FileRootBuilderForTest target,
org.ffd2.austenx.runtime.LexErrorCatcher lexErrorCatcher,
org.ffd2.austenx.runtime.PackratErrorCatcher packratErrorCatcher
) {
...
}
public final org.ffd2.austenx.runtime.BuildStats buildFile(
FileRootBuilderFor builder,
org.ffd2.austenx.runtime.PackratErrorCatcher errorCatcher
) {
...
}
...
}
There is much in the generated class (much of the work is done there), but for the user, only the "build", and "quickBuild"
methods are important.
Putting it together
Remembering from the Lex sections, the lexical analysiser section of Austen generates "Lex", and "Token"
classes. Assuming our tokens block is called ExampleTokens, and the lex block is
called ExampleLex, then we will have a ExampleTokensTable class (for storing tokens),
and an ExampleLexLexParser class (for parsing the tokens). Thus we can do something similar to the following:
String fileText = [... my file text...];
BasicErrorTracker errorTracker = new BasicErrorTracker();
GeneralCommonErrorOutput errorBase = new GeneralCommonErrorOutput("myFile", errorTracker);
GeneralErrorCatcher errorCatcher = new GeneralErrorCatcher(errorBase);
ExampleTokensTable table = new ExampleTokensTable();
ExampleLexLexParser lex = new ExampleLexLexParser();
lex.doParseForNormal(new StringBasedCharacterSource(fileText),table,errorCatcher);
This code, as described above will set up the error interface, and do the lexical analysis pass,
storing the result in table. Errors can be tracked through errorTracker. (More information can
be found in the earlier second on lexical analysis).
Now the lexical analysis has been done, and assuming the "Test" packrat defined above, we can do the next step of packrat parsing:
FileRootBuilderForTest rootBuilder = ...;
...
if(!errorCatcher.isInError()) {
TestPackrat packrat = new TestPackrat(table.getTokens());
packrat.buildFile(rootBuilder,errorCatcher);
}
So, the general gist of things, is first, construct a new TestPackrat, with the tokens from the lexical analysis
(after first checking if there were any errors in the first pass). Next, asking the packrat parser to
build a parse tree, and then instruct a "RootBuilder" object. From here the rest of the parsing occurs. After,
the user can check for errors, from the ErrorTracker, or ErrorCatcher used (see appendix...).
"Quick" building
There are also "quickBuild" methods generated. By "quick" it is just meant that they are meant to be
simpler to access for the user. For each root, there is a "quickBuild" method,
and a "quickAndSimpleBuild" method. They are essentially the same, but the "quickAndSimple"
version combines the lex and packrat error handlers (see below). The above could be accomplished via the following:
String fileText = ...;
FileRootBuilderForTest rootBuilder = ...;
BasicErrorTracker errorTracker = new BasicErrorTracker();
GeneralCommonErrorOutput errorBase = new GeneralCommonErrorOutput("myFile", errorTracker);
GeneralErrorCatcher errorCatcher = new GeneralErrorCatcher(errorBase);
TestPackrat.quickAndSimpleBuildFile(
new StringBasedCharacterSource(fileText),
new TestPackrat.NormalParser(new ExampleLexLexParser()),
rootBuilder,
errorCatcher
);
Build stats (statistics)
The "build" (and "quickBuild") methods return a BuildStats object from the "org.ffd2.austenx.runtime" package (from the Austen support jar).
This provides some information on how the parsing occured. In particular, it helps see the effect
memorisation may have. At the moment, the best thing to do with the BuildStates object is to print it out
(or call toString()). This will provide information on how many tokens were parsed, and how many
"columns" were created. Internally "column" objects are created to parse a "column" of the packrat table
(in other words, a token site). The number of columns created is a reflection on how deep the rule
resolution must go (for a particular token), and the amount of memorisation used. To put it simply - more
columns is bad, but if you find that that the number of columns created varies little for different inputs
then you are probably doing enough memorisation - you may want to reduce what is currently been done.
The BuildStates will also list the number of memorisation usages for each memorised (concrete)
pattern. From this, it is easy to see which patterns need memorisation, and which do not. You will find
that most patterns get rechecked at a particular token, and so memorisation is not needed. Even at
sites where memorisation is helpful, it probably is not worth the memory/performance tradeoff...
Error handling
This really ought to be somewhere else but some notes need to be said about error handling. Note above the use of the
GeneralErrorCatcher class. One does not need to use this, but it is provided as a utility class (using my strange error
tracker tool). Instead of that someting that implements the ParserErrorCatcher interface can be used instead. This interface,
in the "org.ffd2.austenx.runtime" package is defined as follows:
package org.ffd2.austenx.runtime;
public interface ParserErrorCatcher extends LexErrorCatcher,PackratErrorCatcher {
}
This does not help much, unless we look at the LexErrorCatcher,and PackratErrorCatcher interfaces. These can
be found in the same package "org.ffd2.austenx.runtime" and are as follows.
package org.ffd2.austenx.runtime;
public interface LexErrorCatcher {
public boolean invalidToken(String tokenText, int lineNumber, int characterNumber);
}
and...
public interface PackratErrorCatcher {
public void incompleteParse(
BaseToken lastParsedToken,
BaseToken lastAccessedToken
);
public void failedParse(
BaseToken lastAccessedToken
);
public void incompleteParseWithErrorHint(
BaseToken lastParsedToken,
BaseToken lastAccessedToken,
String errorHint
);
public void failedParseWithErrorHint(
BaseToken lastAccessedToken,
String errorHint
);
}
(In the actual files there are more comments...)
These two error catchers are provided seperately for the lexical and PEG analysis (yes, the interface probably ought to be
called "PEGErrorCatcher"). If one does not use the "quickBuild" functions, they need to provide a LexErrorCatcher,and PackratErrorCatcher
object at the appropriate times.
If we look at LexErrorCatcher first, we see just one method "invalidToken", which is called when text that cannot be parsed
is encountered. Usually, "token" text will be a single character. The "lineNumber" and "characterNumber" are dependent on correct use
of the "newline" command (see above).
If we look at PackratErrorCatcher things are slightly more interesting. The method "failedParse" is called when no
PEG pattern is matched at all. The token given is the token last checked by the pattern matching algorithm, and is usually
a good indication of where things went wrong. the "incompleteParse" method is called when some pattern has been matched,
but things failed latter on. In this case "lastParsedToken" is the token at the end of the last thing consumed, and
"lastAccessedToken" is the token that was last checked (or rather has the highest index in the tokens array). This token
is usually a very good indicator of where the problem is.
Error hints 1
The methods with "WithErrorHint" appended to their names, are if an error hint has been tagged in the parsing code. Please see
the section on marking error hints, and the section on general error handling for
more information.
The BaseToken
The BaseToken interface looks as follows:
package org.ffd2.austenx.runtime;
public interface BaseToken {
public int getIntValue();
public long getLongValue();
public String getStringValue();
public boolean getBooleanValue();
public double getDoubleValue();
public int getLineNumber();
public int getCharacterNumber();
public BaseToken[] getArrayElements();
}
Most of that will not interest the user, but the methods "getLineNumber()" and "getCharacterNumber()" will allow the
user to access the line and character numbers of the offending token, and "getStringValue()" will usually give something
useful for the end appliation-user, though in cases of "void" tokens, a constant would need to be set appropriately (otherwise,
you will just get back "void"), and in the case of strings, as defined above, the quote marks would be missing.
Left Recursion
Now that the basics of the use of Austen has been described, along with a description of
the general interaction with generated code, it is time to move on to the more novel aspects. With
PEG style parsers, left recursion is always a hot topic. Austen handles left recursion with
some ease, and goes a little further than other similar parser tools (that I've seen). First, an
introduction on the basics of left recursion, and then a discussion on how order can matter.
Simple direct left-recursion
Direct left-recursion is when a pattern references itself as a sub-rule, with that reference being (or
possibly being) the first thing matched (that is, the first thing on the left of the pattern description).
As was mentioned above, this causes problems with some recursive-descent parsers, because it creates
an infinite recursion. It can be argued though that left-recursion is useful for making some
grammatical constructs more easily represented.
The following is the text book example of a case of left-recursion:
pattern Expression1 {
Plus ( Expression1:first PLUS_SYMBOL Expression1:second )
Number ( NUMBER:value )
}
You will note that Expression1 references itself in the sub-rule tagged "first", and this occurs on
the left. Normally, with a recursive-descent algorithm, or one of the original packrat algorithms, this
would cause serious problems. Austen is fine with this, and will happily parse something like
"1+2+3". The question is then, what does the parse tree look like ? Is the tree left or right
associative - does it loook like "A" or does it look like "B" as in the following image?
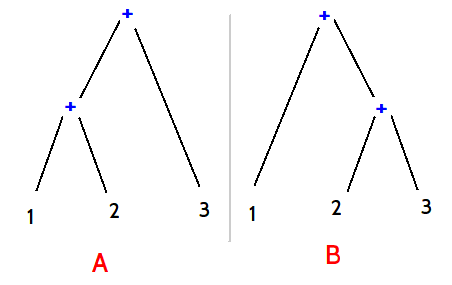
The answer is, it looks like "A", which might be a shock to some. That is, Austen makes left-associative
trees by default, when working with left-recursion. Well, sort of. It does if the option split is at the pattern
level - that is, is part of a multi-option pattern. Consider the following pattern:
pattern Expression2 (
{ Expression2:first PLUS_SYMBOL Expression2:second } |
{ NUMBER:value }
}
Expression2 is grammatically the same as Expression1, but the code produced is quite different
(see above). Furthermore, the tree built would be the right-associative tree of "B" from the above diagram. This
is due to Austen being a bit smarter with the multi-option patterns than in general. This may change in the future, to
be left-associative in all cases (unless otherwise requested).
Also, there ought to be a way to specify left or right associativity, and there might be actually, but I've
forgotten it if so. In a very near future version there will be! There is a sort of way of specifying it, as will be seen
with the next section.
Simple Indirect Recurssion
Indirect recursion is when the sub-rule referenced is not the same pattern as the referencer, but in that
sub-rule there is a reference (on the left in this case) for the initial pattern. The following is an example
of this:
pattern SimplePlus ( Expression3:first PLUS_SYMBOL Expression3:second );
pattern Expression3 {
Plus ( SimplePlus:plus )
Number ( NUMBER:value )
}
Again, Expression3 is grammatically the same as the other patterns described above, but this time
Expression3 does not directly refer to itself, but by referencing pattern SimplePlus,
it does indirectly. In general this causes the exact same problems as direct left-recursion. For
Austen though, it is no problem, and should respond the same, and build the same parse tree (effectively)
as Expression1.
A Note on Memorisation
The reader may remember that Austen is, at the moment, essentially a packrat parser algoritm, and
that by default pattern evaluations are stored. Recalling previously, this can be avoided for specific rules
by using the "pattern*" syntax. Note that using memorisation for a pattern has no effect on the treatment
of left-recursion. None at all, because Austen is awesome.
Complex Recursion
Now, it's time for some cool stuff. What about the case when the there are more left-recursion options? Consider the following:
pattern Expression4 {
Plus ( Expression4:first PLUS_SYMBOL Expression4:second )
Times ( Expression4:first STAR_SYMBOL Expression4:second )
Number ( NUMBER:value )
}
The above is the next textbook case for left-recursion, when there are two instances of left recursion.
Now we can expressions with "+" and "*" symbols connecting (I usually write STAR_SYMBOL, because ASTERICK is
too long and harder to spell). Now, what do we get if we parse "1*2+3"? What about if we parse "1+2*3"? Well,
the following diagram will show you:
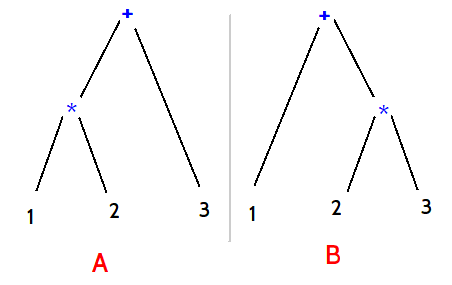
Now the associatity changes depending things, and it does this because option order matters. In
other implementations of PEG parsers, the left-recursion algorithms do not handle order well; they produce
the same right-associative trees regardless.
Why does the order make sense?
Now the question is, why does the ordering given produce the given parse trees? Is the following different?
pattern Expression5 {
Times ( Expression5:first STAR_SYMBOL Expression5:second )
Plus ( Expression5:first PLUS_SYMBOL Expression5:second )
Number ( NUMBER:value )
}
Yes, Expression5 will produce the opposite parse-trees from Expression4. It makes sense,
to me, because we assume the ordering specifies precedence. The first option is the highest. If we find
a match for the first option, we stick with it. With left-recursion, this becomes confusing. But, let's
consider "1*2+3". Looking at Expression4 the first pattern we try is the first option, is that with
the "+" symbol. So, you could imagine trying first="1*2", followed by a "+", followed by second="3".
This matches, so that is the resolution for that pattern.
Now consider "1+2*3". Again, we try the first option, by trying to consume
first="1", followed by a "+", followed by second="2*3". That works, so we
leave it at that and that is the pattern match.
Of course, if you are up on left-recursion in PEG parsers, you are going to say "you can't just do
that!". I'm not saying that's how the algoirithm works - it's not, but that's how I understand the result.
It should be noted that the following is not a very good idea:
pattern Expression6 {
Times ( Expression6:first STAR_SYMBOL Expression6:second )
Number ( NUMBER:value )
Plus ( Expression6:first PLUS_SYMBOL Expression6:second )
}
The above will parse "1*2+3" by only consuming "1*2", and will parse "1+2*3" by only consuming "1". I
will leave that as an exercise for the reader to ponder why.
Does it work with "simple" patterns
No. Consider the following:
pattern Expression7 (
{ Expression7:first PLUS_SYMBOL Expression7:second } |
{ Expression7:first STAR_SYMBOL Expression7:second } |
{ NUMBER:value }
);
Expression7 will match the input, but build a right-associative tree, regardless of the input
being "1+2*3", or "1*2+3". It would be possible, I think, to get this right, but it is more bother than
it is worth (things get tricky when the first sub-rule is only a possible match). Be thankful for what you've
got, and quit complaining.
Option Grouping
From the above, with multi-option patterns the order is important, and options listed first have higher
precedence, and will group with left-associativity, in comparison with subsequent options, which group
with higher-precedence ones with right-associativity. This may cause some problems with options that
ought to be grouped with left-associativity, but are not exactly the same and need to take up two options.
An example of such a thing is to add the subtraction and division operators to our expressions, like so:
pattern Expression8 {
Plus ( Expression8:first PLUS_SYMBOL Expression8:second )
Subtract ( Expression8:first MINUS_SYMBOL Expression8:second )
Times ( Expression8:first STAR_SYMBOL Expression8:second )
Divide ( Expression8:first SLASH_SYMBOL Expression8:second )
Number ( NUMBER:value )
}
Now, if we use Expression8 to parse "1+2+3-4" for example, we get a parse tree
like the one depicted as "A" in the following:
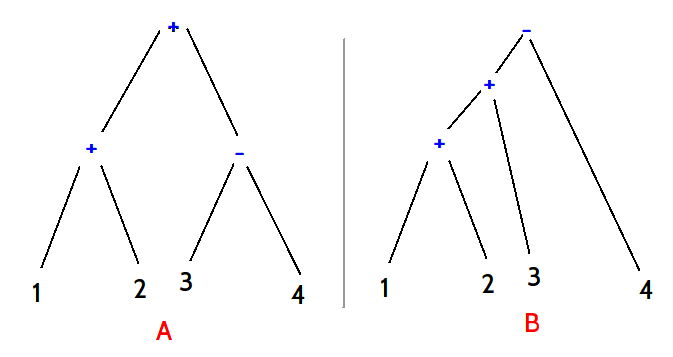
This tree might be seen as problematic, because it means the expression evauates to (1+2)+(3-4)=3+-1=2, which is
correct, but,
ideally, we may want a tree like "B", which evaluates to ((1+2)+3)-4=6-4=2. That is, we may want both addition and
subtraction to be mutually left-associative. Well, Austen doesn't forget
the little people, so in order to get this behaviour, one can group options into equivalent priority groups,
which will left-associate with(in) each other. To do this, just group them with curly brackets (in technical terms). For
example:
pattern Expression9 {
{
Plus ( Expression9:first PLUS_SYMBOL Expression9:second )
Subtract ( Expression9:first MINUS_SYMBOL Expression9:second )
}
{
Times ( Expression9:first STAR_SYMBOL Expression9:second )
Divide ( Expression9:first SLASH_SYMBOL Expression9:second )
}
Number ( NUMBER:value )
}
Complex Indirect Recurssion
Does this work with indirect left-recursion? How about with indirect right-recursion? The answer is, yes.
Okay, How Does It Work
For now, the answer is "magic", but I will write up the algorithm as soon as I can. I will say it works
by a process of, sort-of, "reinterpreting" the pattern resolution on the right (it should be noted that
left-recursion problems only occur when there is a recursion on the right, and one on the left - of the recursion on the right...).
Extended PEG
Another area that Austen is developing in is with regard to extending
the Parsing Expression Grammar framework, but adding some new and
exciting features with regard to matching. How useful these additions turn
out to be remains to be seen though. Also, with time, the extensions
may allow shifting of some of the semantic parsing onto the Austen grammar
file, and away from the user code.
PEG Variables
At the heart of the extensions to PEGs that Austen implements revolve
around variables. This is possible with PEG style grammars due to the
"consumptive/back-tracking" nature of the parsing algorithms.
Declaring Variables
The first step is to declare the variables to be used in a pattern (or
a pattern choice). Variables must be declared, and must be given an initial
value. The initial value will determine the type of the variable. So,
for example:
pattern Extended1 [$x=0 $y="Hello"]( NUMBER NUMBER );
Extended1 is a very simple pattern that declares two variables (but does
not use them). Variables are marked by having a dollar sign in front (eg "$x"). The
two variables declared are of type int for "$x", and string for $y. Note
that there are no commas between the declarations.
With multi-option patterns, the variables are set for each option. You cannot
currently set them for the entire pattern (this will change). So for example:
pattern Extended2 {
Number [$x=0]( NUMBER NUMBER )
Words [$y="Hello"]( ID ID )
}
Tagging Variables
One thing that can be done with a variable is to tag it. Like tagging tokens and
sub-rules, tagged variables are returned to the user. They function like tokens, and
so have top-level and sub-level interpretations. Tagging is done with a similar syntax
too, so consider the following example:
pattern Extended3 [$x=0 ]( NUMBER:value $x:x NUMBER );
In the above case, variable $x is tagged "x". Tagging a variable will mean that its
value at the point of tagging will be returned to the user, as for tokens. So for example, consider
the following user of Extended3:
pattern User ( ID:id Extended3:ext );
From this you would get a Peer interface for the User pattern as follows:
public interface UserPatternPeer {
public void end() ;
public void addExtended3ForExt(int xExtra, int value) ;
}
It should be noticed that "extras" come before tokens, even if they are used after a tagged token.
Setting a PEG Variable to a token value
Initialising a variable, and then returning that value to the user, is somewhat pointless, so the next thing
that can be done to a variable it to set it to the value of a consumed token. This is done by using the
assignment operator (a "="), to link a variable to a token. For example, consider the following:
pattern Extended4 [$x=0 ]( $x=NUMBER:value $x:x NUMBER );
With Extended4, the generated user code is the same, but now, the "xExtra" given will not
always be zero, but will match the value of the first token consumed (eg, the sames as "value").
Tokens do not have to be tagged, and Austen should give an error if the type of the token does
not match the type of the variable. Sorry for the strangeness of having to give an initial value
to something that will be set to something else anyhow. Such is the way it goes.
Updating a variable
Updating a variable is currently very limited (this is all experimental stuff), but some useful
things can be done. Again, this is just done by using the assignment operator. Consider the following:
pattern Extended5 [$x=0 $y=0 ]( $x=NUMBER $y=NUMBER $x=$x+$y $x:x );
The above consumes a NUMBER token, and stores the value in $x, and
then consumes another NUMBER token, and stores the value in $y. At that
point in pattern matching the variable $x is reassigned to be the total of the
two variables, and then it is tagged (meaning that total value is given to the user).
The possible operators at the moment are "+", "-", "/", "*", and some boolean ones. This
will expand later (strings concatenate under "+"). Also, post-fix uniary operators "++", and "--" available (and work as
expected).
Note also that tokens cannot be used in more complex variable based expression. That is,
you cannot write "$x=$x+NUMBER". I am not sure if that will change in the future (I think
it will lead to messiness). You can write "$x=$x+1" (or even "$x=2*3+1").
Counting items
Just briefly, there is a use for the extended PEGs so described, that helps deal with the
quirks of the code Austen currently generates. The problem comes with sub-elements, as sometimes
it might be useful to know how many such elements there are earlier than normally given. For example:
pattern Count1 ( NUMBER:initial { NUMBER:next }* );
When Count1 is used, the PatternPeer instructed does not know the number of tokens taged "next"
that it will receive. This may be annoying if they are stored, as some sort of variable size storage will
be needed, instead of a simple array. A future version of Austen may provide the ability to automatically
store the values in an array, or to provide a count, but in the meantime, extend PEG grammar can help. For
example:
pattern Count1 [$count = 0] ( NUMBER:initial { NUMBER:next $count++ }* $count:numberOfNexts );
The tagging of "$count" is at the top-level, and will provide the number of "next" tagged tokens
to be provided, before the Peer is instructed of those tokens.
Queries
So far, variables are for the most part pointless. They do not affect the actual parsing of input,
so it may seem a bit rich to claim they are an extension to PEG. Well, this is where queries come into play.
Queries are things that are consumed when they are true, and stop consumption, when they are false.
The syntax of queries is a little odd. A query must be surrounded by round brackets, and takes a similar
form to that in many programming languages. For example, to query if a variable is a certain value, use something
similar to the following:
pattern Query [$x=0 $y=0 ]( $x=NUMBER ($x==5) NUMBER );
The above pattern matches two numbers, but the first number must be the value 5 (or be parsed as "5").
Operators include "<", ">","<=", ">=","==", "!=". The comparison expressions can be more complex,
so the following is possible:
pattern Query [$x=0 $y=0 ]( $x=NUMBER $y=NUMBER ($x==$y));
The above will only match if two numbers are consumed, and the first two numbers are the same.
Advanced
The variable and query systems are quite flexible. They in fact form a mini programming language, when
combined with the normal PEG operators. For example:
pattern Factorial [$x=0 $count=1 $result=1 ]( $x=NUMBER $count=$x { ($count<=$x) $result=$result*$count $count=$count+1 }* $x=NUMBER ( $result==$x) );
The above patter first consumes a number, and then calculates the factorial of that number, and then compares that to the next
number consumed. The use of "zero-or-more" operator, "*", effectively makes a "while" loop. Using the maybe operator "?" can
similarly be used as an "if" statement.
Variables and backtracking
It should be noted that when using variables within a section of pattern that maybe consumed (such as
within a "*" block, or a "?" block), if the sub-pattern fails to fully consume, any operations done
on variables during that sub-block, but before the block was determined to fail, will remain in place. For
example
pattern Faulty [$x=0 $y=0]( $x=NUMBER { $x = $x+1 $y=NUMBER ($x==$y) } | { $y=NUMBER $x=$x+y $y=NUMBER ($x==$y) } );
In the previous pattern, Faulty, first a number is consumed, and assigned to variable $x. Then 1 is
added to $x. Then, first,
another number is consumed, and assigned to $y. If $x==$y, then that clause succeeds, the input is consumed,
and the pattern succeeds. If not, the algorithm backtracks (so only the first number is current consumed). At
this point though, $x does not revert to the previous value, and remains at the original value plus one.
Thus, when the next option is tried, to consume another number, add it to $x, and consume a third number, assigned to
$y, and
then query if $y matches $x, then we are not check if three numbers are consumed where the third is the
total of the first two, but rather, we check if three numbers are consumed where the third is the
total of the first two plus one.
I believe this is a more flexible way to do things, as that
means look-ahead results can be stored in variables. If one does not want that to happen, consume the
tokens first, and assign to other variables.
System variables
From version 1.1 on there are now some system variables accessible (but not changeable) from the pattern
matching code. These are accessed as though they are normal variables. As of version 1.1, the following system variables are
available:
- $line This variable returns the line of the token currently at the "cursor" — this is the token
that is about to be read (or the previous token, if no more tokens left to read). This value starts at 1, not zero!
- $char or $character This variable returns the character (within the current line) of the token currently at the "cursor" — this is the token
that is about to be read (or the previous token, if no more tokens left to read). This value starts at 1, not zero!
- $lastline This variable returns the line of the token last matched — this is the token
that was last matched, or the first token, if no tokens have yet been matched. This
is the last token matched by either this rule pattern, or any other one. This value starts at 1, not zero!
- $lastchar This variable returns the character (within the current line) of the token last matched — this is the token
that was last matched, or the first token, if no tokens have yet been matched. This value starts at 1, not zero!
- $error This variable returns the current marked error message, or "" otherwise (see error marking
for more info).
System variable names can be masked by user define similar named variables. If for some reason you must have your own variable
called "$line", for example, you can still access the system version by double dollar signs — that is, "$$line".
Starts at 1
One last time: line numbers and character numbers are reported starting from 1, not zero.
Pseudo tokens (v1.1)
I have called this language features "pseudo tokens" that roughly act like tokens, but are not user specified, and
do not necessarily refer to a concrete token that may be consumed. They
were introduced in version 1.1. They are marked by having their name start with a hash ("#"), and, like
normal token references, are part of the
rule match expressions.
The current pseudo tokens are as follows (note that the names are not actually case sensitive):
- #ANY this is a pseudo token that matches any token. This consumes the token.
- #NEWLINE, or #NEW_LINE this matches if the next read token will be on a new line compared to the last matched token.
- #NOTNEWLINE, or #NOT_NEWLINE, or #NOT_NEW_LINE, or #SAMELINE, or #SAME_LINE this matches if the next read token will not be on a new line compared to the last matched token.
- #MARK this references the next token to be read (or the last one if we are at the end of the tokens),
and must be tagged. It does not consume any input.
It can be used as either a top-level or sub-level token (and will interact with user code accordingly).
- #ERROR this references the current error info, and must be tagged, to return the current error info to
the user. Because it must be tagged (see below), it will return data to the user code, in the form of an message string,
and a reference to the maximally accessed token at the time of parsing the #ERROR pseudo token.
It can be used as either a top-level or sub-level token (and will interact with user code accordingly). Please
see the section on error handling.
- #CLEARERROR,or #CLEAR_ERROR this clears any error hints previously created. Please
see the section on error handling
The only pseudo-token to consume input currently is "#ANY".
An example of usage is as follows:
pattern AlmostComment ( DOUBLE_SLASH {#NOTNEWLINE #ANY} *);
The above example consumes all tokens after a double slash symbol "//" (assumed token "DOUBLE_SLASH" has been defined as such)
until the end of the line (so, roughly matches the single line "// text" comment of c-like languages).
Tagging
Pseudo tokens can either be tagged or untagged, but in the case of the current ones, they either must be
tagged, or must not be tagged. The pseudo tokens "#ANY", "#NEWLINE", "#NOTNEWLINE"/"#SAMELINE", "#CLEARERROR" must not be tagged,
while "#ERROR" and "#MARK" must be tagged (as they would have no purpose otherwise). One might argue that "#ANY" out to be
able to be tagged, but as of version 1.1 you can't. You can combine "#ANY" with "#MARK" to get the desired effect:
pattern TaggedAny ( #MARK:nextTokenValue #ANY);
Error detailing
Currently, if the packrat parsing fails (by failing to get a rule to consume all input), then the user code is notified
with only details about the token last successfully parsed, and the token last examine (which usually gives a good indication
of the location of the error). Version 1.1 of AustenX includes some new features which aim to enable better error handling,
and possibly error recovery. The linking of the features is described in the section on error handling.
One of the components is marking error info.
The current error info
During the packrat parsing a continuously updated reference to the "best" error information is stored. How this
is meant to be useful is a bit tricky to explain, and mostly untested. Basically, the idea is, in variours pattern rules
a helpful message is noted, that is to be provided to the end user, if parsing has got to a certain point, but fails after.
Marking current error info
To set the current error info, one must set the error message in the rule, after some tokens/rules have been matched,
but before the entire rule has been matched (I'm guessing, maybe it turns out there are times to do otherwise). Errors
are "marked" by stipulating a text message inside a "[[ ... ]]" block (that is, the double square brakets indicate
error marking). This is best seen in an example:
pattern Method (
ID:methodName
LEFT_ROUND
[[ "expecting a ',' or a closing ')'" ]] //**1
{ Expression / COMMA_SYMBOL }?
RIGHT_ROUND
LEFT_CURLY
[[ "expecting a closing '}'" ]] //**2
Statement:s
RIGHT_CURLY
);
In the above example, there are two instances of marking an error. Error messages can also be combined from general expressions,
by just listing the components one after another (no comma) — eg., "[[" EXPRESSION ... EXPRESSION "]]" . So, for
a rather contrived example:
pattern Odd [$x = 4, $number=0 $id="" $y="happy"](
ID:name [[ "Expecting:" $x+3 " " $y " so there" ]] $value=NUMBER ($value==$x+3) $id=ID ($id==$y)
);
See the error handling section for more info.
User supplied variables
Like for the lex parser, the user code can also supply values to the packrat parser in the form of parameter variables. Like
the lex form complex types, using user interfaces, can also be used, to enable feedback to user code during the parsing process.
As can be seen in the appendix on indentation sensitive parsing, this interaction has some very
useful applications.
Specifying user parameters
To specify user parameters, one stipulates them at the top of the packrat definition, where the parser is named. So, for example:
peg ExamplePEG(int number, string word) tokens Example{
...
}
In the above example, two user supplied parameters are specified: an integer named "number", and a string variable named "word". They can
now be accessed by pattern rules in the same way that normal variables are accessed (so, they have a dollar sign, "$", in front
of their names). For example:
pattern WordMatch[$foundWord ="" $foundNumber] ( $foundWord=ID ( $foundWord==$word ) $foundNumber=NUMBER ( $foundNumber>$number) $foundNumber:foundNumber $number:inCaseYouForgot );
In the above example, an ID is consume, and a NUMBER is consumed, but the rule only matches if the ID consumed is the same
text as the supplied value for "word", and if the NUMBER consumed is greater than the value for "number" supplied. The user
code receives the consumed number, and the original number provided as a parameter.
Complex type parameters
As with the lex parsing, more complex data types are supported. They are also defined using the user interface definition
framework (and a user object using a defined interface definition can be both used in a lex parser and a packrat one — in fact this
connection is very important).
So, a similar example to the one used for lex parsing, is as follows:
interface Happy {
boolean flipCoin();
int convertHex(string base);
int add(int first, int second);
void notifyOfCat();
}
peg ComplexPeg(Happy h) tokens Example {
pattern WordMatch[$foundWord ="" $foundNumber] ( $foundWord=ID ( $foundWord==$word ) $foundNumber=NUMBER ( $foundNumber>$number) $foundNumber:foundNumber $number:inCaseYouForgot );
}
Example of use
To finish off this section, a few possible uses for the variable mechanism shall be given.
A simple SGML parser
The first example is a simple SGML parser, by which I mean, something like an XML parser, but where an opening
tag does not always need a closing one. So for example, the following ought to be parsed:
<ul>
<li>One
<li>Two
</ul>
The following pattern should do such a thing:
pattern SGML {
Matched [$name="" $end=""](
LESS_THAN $name=ID GREATER_THAN
SGML:bodyElement*
LESS_THAN SLASH $end=ID GREATER_THAN ($name==$end)
)
Unmatched (
LESS_THAN $name=ID GREATER_THAN
SGML:bodyElement*
)
Text ( ID* )
}
Note the cheap way the body text has been handled. This is just to accommodate the tokens that
have been used to this point. Though, it should be pointed out that a proper implementation
with other tokenisation is still somewhat tricky (I do not think impossible, but would
require clever use of the trigger command, and modes in the lexical analyzer), and this may be a good example where a scanner-free
parser is better (so, look forward to future releases of Austen...).
Using functions for non-nested elements
SGML allows unclosed elements that are not nested. Examples of this within HTML are
the "<p>" and "<li>" elements. In the above definition, the text "<p>Paragraph 1<p>Paragraph 2</p>" results
in "paragraph 2" being nested in "paragraph 1", whereas it is desired that "paragraph 2" start a new paragraph element. To
do this with AustenX, we will need the support of a user object, to tell the parser
what elements are nestable and what are not.
The user interface for this object should be something along the lines
of:
class NestableDetails {
boolean isEndsCurrent(String current, String newTag);
}
Then, assuming the PEG has been given an instance of "NestableDetails", called "nestDetails", we
would rewrite the above SGML definition as so:
pattern SGML {
Matched [$name="" $end="" $child=""](
LESS_THAN $name=ID GREATER_THAN
{
!{ LESS_THAN $child=ID ( $nestDetails.isEndsCurrent(current: $name, newTag: $child) ) }
SGML:bodyElement
}*
LESS_THAN SLASH $end=ID GREATER_THAN ($name==$end)
)
Unmatched (
LESS_THAN $name=ID GREATER_THAN
{
!{ LESS_THAN $child=ID ( $nestDetails.isEndsCurrent(current: $name, newTag: $child) ) }
SGML:bodyElement
}*
)
Text ( ID* )
}
With the text "<p>Paragraph 1<p>Paragraph 2</p>", assuming isEndsCurrent(current: "p", newTag: "p") returns
true, then option "Matched" will consume first "<p>Paragraph 1" (first bodyElement is SGML.Text), and
then fail to consume the second "<p>" (given the "not followed by), and then fail to parse while looking
for the end tag. Then the "Unmatched" option will be tried, again consuming "<p>Paragraph 1",
again stopping at the second "<p>", but the rule will match overall as no closing tag needed.
The user of this rule will then handle the next "<p>Paragraph 2" part (think recursively).
This approach has some redudant calculation, but should work. AustenX is probably not
the best way to write a SGML parser.
Coverting a possible token to a fixed value
This use might not make any sense to a non-user of AustenX but because of the quirks in the way AustenX works,
sometimes the parsing process can lead to strange interactions with the user code. An example of this is when
one has a keyword that may or may not appear in a rule. A good example of this is the "static" keyword in Java, so
consider the following rule:
pattern JavaMethod ( PUBLIC_KEYWORD STATIC_KEYWORD:isStatic? LEFT_ROUND ... RIGHT_ROUND ... );
In the above example I've missed out a lot of important bits, but hopefully the reader gets the gist of
it. The important bit is the "STATIC_KEYWORD:isStatic?" bit. This means, maybe match the STATIC_KEYWORD token
(which we can assume matches the text "static"), and if matched, tag with "isStatic". This token match, because
it is a possibility, will be marked as a sub-level token, and cause a "Peer" interface to be required, with
a method something like:
public interface JavaMethodPeer {
...
public void addIsStatic();
}
The problem with this, is that the user probably wants to know if the method is static or not when
it is first notified of the JavaMethod match, rather then in subsequence processing of the JavaMethod node's children (see
all the stuff above about rule matching). Using variables we can provide this by rewriting the rule as:
pattern JavaMethod [$isStatic = false]( PUBLIC_KEYWORD {STATIC_KEYWORD $isStatic=true}? $isStatic:isStatic LEFT_ROUND ... RIGHT_ROUND ... );
The above rule now shifts the notification of being static to the "top level" (eg, in an "addJavaMethod(..., boolean isStaticExtra,...);" method).
Pay close attention to the order of things, the grouping of the keyword and the changing the variable value, and the subsequent
tagging of the $isStatic variable for user consumption (now at a "top-level" position).
Appendix 1 : user interface definition
This section details defining user "interfaces", which are essentially interfaces to the target language
user code, and used as user types in Austen. They are used by both the lex and packrat parsers to allow interaction with user code
during the parsing process, and in spite of their simplicity, allow a lot of potential, without
the loss of language independence aspired to by AustenX (even though they are inspired by Java, and
similar languages).
Declare an interface
It is simple to declare a interface; one does so in a similar way to that in Java. They can be defined
in the input files in the same places lex and packrat blocks can be define. So for example:
output x.y;
interface MyClass {
int getRandomInt();
void notifyID(String id);
boolean isXLessThanY(int x, int y);
}
The above is the definition of class that has three methods. The keyword "class" can be used
interchangeably with "interface".
Generated code in Java
In Java, the above interface definition would result in a Java interface called MyClassUser
in the file MyClassUser.java, in the package "x.y.user". This file would look roughly
as follows:
package x.y.user;
public interface MyClassUser {
public int getRandomInt();
publicvoid notifyID(String id);
publicboolean isXLessThanY(int x, int y);
}
So, a straightforward mapping, which to some may seem odd. Maybe it seems better to be
able to specify the format of external classes for AustenX to be able to access, instead
of AustenX creating an interface, but the approach used fits better with the focus of
language independence. Outside of Java, the resulting generated code may look very different
(in form as well as syntax) of the specified AustenX class. It just so happens, being
designed based on Java syntax results in a close correspondence.
Appendix 2 : making an indentation sensitive parser
In this section we describe an approach, using AustenX, to creating a parser that
is indentation sensitive (IS), like Ruby, Python, etc... An example parser is given, along
with source code to create a parser that converts a simple indentation sensitive language
into a C-like curly-brace language.
What do I mean by indentation sensitive?
In the following I am refering to the case where the identation of text
has some reflection on the parsing process. The example in mind is where the
indentation specifies the blocking of parsed elements, in a similar way to the
use of curly brackets ("{}") in C-like languages, or "begin...end" in Pascal like
ones.
What is the problem?
As traditionally given, parsers like Austen will have difficulty parsing IS
style languages. Probably, an initial preprocessing pass is needed, with block delimiters
added in. It would be nice to be able to parse the text straight though. Austen in particular
seems set against IS languages with a tokenisation step that removes whitespace.
But now it is possible?
With version 1.1 of Austen new features have been added that allow IS parsing
in a relatively straightforward way. What is required goes beyond the inbuilt language
features, but the inbuilt language features allow the power to do IS. In particular,
the addition of user specified objects, which allow parser interaction, enables the
user to fill in the missing gaps required for IS. Having said that, the additional
work is minimal, and is reproduced here for general use.
IMPORTANT NOTE
In the following it is important to remember one vital fact. That fact is,
Austen notes line numbers and character numbers with the first position or line
being denoted by "1", and not zero. That is (1,1) is the first line and character.
The Indentation Sensitive example
In the following we will work through important parts of an example of IS parsing that is provided (see below),
that allows parsing of input of an imaginary language. An example of this language is the following:
class Happy
function moo(x)
x = 5
function goo(isThing)
if(isThing)
print("Thing!")
else
print("Not thing!")
print("Oh well")
class NoFunctions
The example tool allows input in the above language and converts it to a similar language that uses C-like "{}" blocking.
Downloading the example
The example files as source and binaries can be downloaded from here.
Step 1 — some external code
To get IS parsing to work, we must first define an external user object that will
do some of the heavy lifting for us. The user interface for
the user object needed will be define as follows:
interface IndentTracker {
int getIndent(int line);
void newLine();
void newWhitespace(String whitespace, int cursorCharacter);
}
The "IndentTracker" object will allow us to link the lexical parsing phase with the
PEG parsing phase, and will allow us to store information about whitespace that is
otherwise lost in the parsing. An example implementation of this user object is as follows:
public class IndentTracker implements IndentTrackerUser {
private int[] indentCounts_;
private int currentLine_;
private final int bufferIncrease_;
private final int tabSize_;
public IndentTracker(int bufferIncrease, int tabSize) {
this.bufferIncrease_ = bufferIncrease;
this.tabSize_ = tabSize;
this.indentCounts_ = new int[bufferIncrease];
}
public void dumpIndents() {
for(int i = 0 ; i < currentLine_ ; i++ ) {
System.out.println(i+":"+this.indentCounts_[i]);
}
}
public int getIndent(int line) {
return indentCounts_[line-1];
}
public void newLine() {
currentLine_++;
if(currentLine_>=indentCounts_.length) {
int[] old = indentCounts_;
this.indentCounts_ = new int[old.length+bufferIncrease_];
System.arraycopy(old,0,indentCounts_,0,old.length);
}
indentCounts_[currentLine_] = 0; //I know not needed but I like things initialised
indentSet_ = false;
}
public void newWhitespace(String whitespace, int cursorCharacter) {
if(cursorCharacter==1) {
int count = 0;
for(int i = whitespace.length()-1 ; i>=0 ; i--) {
if(whitespace.charAt(i)=='\t') {
count+=this.tabSize_;
} else {
count++;
}
}
indentCounts_[currentLine_] = count;
}
}
}
The above is a Java class implementing the user interface "IndentTracker". Essentially
it keeps track of the indentation whitespace of each line of the file. The "newWhitespace()"
method will be used to register whitespace during the parsing, but only pays attention if the
whitespace is supplied at the start of the line.
The above understands whitespace to be made of either spaces or tab characters. Tabs
are translated to a specified number of spaces, given in the constructor. Newline characters
do not need to be taken into account as they will never be part of the whitespace given.
Step 2 — lexical parsing
The next step is to set up the lexical parsing phase so that the indentation information
is stored correctly. This is relatively straightforward, as there are only two things
to do: first, notify the IndentTracker object of new lines, and second, notify the IndentTracker
object of whitespace. The only tricky part is making sure this is done for all times
it is relevant — that is, make sure to notify of new lines in every "mode" (such
as comment mode). Future versions of AustenX will probably have an "on newline" block
for actions that occur when a "newline" command is encountered to make this easier.
The lex block will look something like the following:
lex Test(IndentTracker tracker) tokens Indent uses GeneralDefs {
initial Normal;
end {
tracker.newLine();
}
mode comment {
pattern ( NEWLINE ) { newline; tracker.newLine(); }
...
}
mode simpleComment {
pattern ( NEWLINE ) { newline; tracker.newLine(); switch Normal; }
...
}
mode Normal {
pattern ( NEWLINE ) { newline; tracker.newLine(); }
pattern ( {" "|'\t'}+ ) {
tracker.newWhitespace(whitespace: text, cursorCharacter: char);
}
...
}
The above is for a language that uses C-like comments (like AustenX does). Note
that the whitespace within comment sections does not need to be acknowledged (though
comments of this form create strange behaviour if used oddly — explained later).
Basically, the above just notifiers the tracker of new lines and whitespace
when relevant. One needs to understand/remember function calls, and the "char" and
"text" system variable (see the advanced lexical section).
The result of the above code is to create a table of indentation for each line.
The next and final step then will be to use that information in the PEG parsing
step.
Step 3 — PEG parsing
The last part involves connection with the PEG parser. We now have information about indentation set
up in the lex pass and using features new to version 1.1 of AustenX, we will use that information to
inform blocking in the PEG parsing.
The following is an extract from the example project which illustrates IS.
packrat* IndentTest(IndentTracker tracker) tokens Indent {
...
pattern Class [$indentBase=0 $currentIndent=0](
$indentBase = $tracker.getIndent(line: $line)
@CLASS_KEYWORD:keyword ID:name
{
$currentIndent = $tracker.getIndent(line: $line)
( $indentBase < $currentIndent ) //Query
ClassElement:elements
}*
);
pattern ClassElement {
FunctionDef [$indentBase=0 $currentIndent=0](
$indentBase = $tracker.getIndent(line: $line)
@FUNCTION_KEYWORD:keyword ID:name LEFT_ROUND { ID:p / COMMA_SYMBOL}? [[ "Expecting closing round bracket" ]] RIGHT_ROUND
{
$currentIndent = $tracker.getIndent(line: $line)
( $indentBase < $currentIndent ) //Query
-Statement:statements
}*
);
}
...
}
As can be seen above, a number of more advanced features have been used. The definition of a Class looks complicated but
sets the scene for the similar process of handling function definitions. In both cases we use ePEG features. The process
is roughly as follows:
- Declare two variables: $indentBase (which is used to store the initial indentation), and $currentIndent (which is
used to track indentation of possible child elements)
- Read in the current indentation. This is done by using the IndentTracker object supplied by the user (and
initialised during the lexical parsing phase — this is the same instance passed to the lex parser). In
particular, the "getIndent" method is called, passing in the current line (as obtained from the $line system variable).
- Next the CLASS_KEYWORD token is attempted to be consumed. When we accessed $line previously we were refering to the
line of this token (as $line is the line of the next read token). This indentation is our reference point.
- We then consume the name (not really important).
- Now we enter a "zero or more" block. To match this block we:
- read in the indentation of the line of the next token to be read (the first token of any child).
- query that the base indentation (of the CLASS_KEYWORD token) is less than the indentation of the next
token (stored in $currentIndent)
- Lastly, if the previous query succeeds, we try to consume a class element like normal
As you can see, the process for the ClassElement.FunctionDef pattern is very similar: first, make a note of the indentation
of the starting token, then compare each child's indentation to that base line indentation, and reject when it matches or
falls below the initial indentation level.
Simplifying things
Depending on need the above could be simplified by making the requirement that classes start with no indentation. The
current way it is written classes can be initially indented as desired, but one could easily make the following change to
require no initial indentation:
pattern ClassStrict [ $currentIndent=0](
( $tracker.getIndent(line: $line) == 0 )
@CLASS_KEYWORD:keyword ID:name
{
$currentIndent = $tracker.getIndent(line: $line)
( $currentIndent > 0 ) //Query
ClassElement:elements
}*
);
Resulting behaviour
Given the above, the parser generates parses the input in what seems like an intuitive manner to me. Of note though is
that indentation does not need to remain strictly consistent within children, and may drop below the indentation of the parent.
For example, in our language we could write the following:
class Happy
function moo(
x, y
)
x =
y
or...
class Happy
function
moo(x)
if(
x)
print("Moo",
"cow"
)
print("outside if")
Personally, I think that is appropriate, but if required, more strict indentation could be enforced with
slightly more work on behalf of the IndentTracker code. I will leave this to the reader, but would suggest looking
at having an "isIndentAlwaysAbove(int queryLevel, int startLine, int endLine)" method in there somewhere.
Multi-statement lines
The above definition allows for multiple statements (or even function defs) on the same line. Many people seem to
dislike multi-statement lines. I think such people are odd, as in an age of wide screen monitors, that can sometimes
be useful (more informative than a "fold"). So, the following is valid:
class Happy
function moo(x)
if(x)
print("Moo" ) print ("cow")
Where things get strange is when a child element is on the same line as the parent. For example:
class Happy
function moo() foo()
function goo(x)
if(x) zoo()
The example IS project, as given, will not parse the above, as it falters on the definition of "moo()".
It does this because the "foo()" statement has the same indentation as the "function" keyword (as they are
both on the same line). From the parser definition, this puts "foo()" outside the function block, and thus "floating"
in the class definition (which is an error). If a similar procedure was adopted for the "if(x)" statement, this would parse,
but because both "if(x)" and "zoo()" share the same indentation, they are treated as two separate statements,
and would be the equivalent of the following:
function goo(x) {
if(x) {
}
zoo()
}
It turns out though, the example IS project will in fact parse "goo()" correctly (or at least, the way I'd like,
which is to include the "zoo()" statement as the dependent statement of the "if(x)"). The way this is achieved is seen
by looking at the rule for the "if" statement, which is quite involved:
If [$indentBase=0 $currentIndent=0](
$indentBase = $tracker.getIndent(line: $line)
@IF_KEYWORD:keyword LEFT_ROUND -Expression:conditional RIGHT_ROUND
{ #SAMELINE -Statement:statements }* //Absorb same line statements
{
$currentIndent = $tracker.getIndent(line: $line)
( $indentBase < $currentIndent ) //Query
-Statement:statements
}*
{
//Maybe have an else - indentation of ELSE_KEYWORD must match the IF
$currentIndent = $tracker.getIndent(line: $line)
( $indentBase == $currentIndent ) //Query
ELSE_KEYWORD
{ #SAMELINE -Statement:elseStatements }* //Absorb same line statements
{
$currentIndent = $tracker.getIndent(line: $line)
( $indentBase < $currentIndent ) //Query
-Statement:elseStatements
}*
} ? //ELSE is a maybe
);
The definition for "if" is more involved than for functions and classes, even excluding the "else" section
(which probably makes "if" the most complex thing). The trick is the line which looks like:
{ #SAMELINE -Statement:statements }* //Absorb same line statements
This line uses the "pseudo token" #SAMELINE to absorb all statements on the same line as the IF_KEYWORD. Or
rather, it sort of does. The #SAMELINE token consumes if the next token to be read is on the same line as the last token
read (which in this case is the end of the "if()" block - or the right hand rounded bracket - or at least,
this is for the first statement on the line). This is repeated zero
or more times, which is where the interesting behaviour arises. After we have absorbed one statement on the same line
we may in fact be on a new line, and this may give strange behaviour. For example, consider the following:
if(x) foo() moo(
) zoo()
The above would actually parse as:
if(x) {
foo()
moo()
zoo()
}
The definition used actually states: consume an statement as long as it starts on the same line as the end of the
last statement, or the right bracket of the "if" statement. I actually like this behaviour, apart from allowing
terrible style (which is not a plus), it seems "fair enough" to me (that is, it doesn't fail on terrible style, but
still encourages good style).
For the concerned, other methods for having same line statements are possible that would give other behaviour.
One would be to make a note of the initial line number, and then consume statements
as long as we are on the same line still (continually reading the "$line" system variable). This is more involved though
and left as an exercise to readers who insist on different behaviour. One can of course just say "no, no multi-line statements",
which I guess is many people, but I'll vote multi-line any day.
A bit more on multi-line "ifs"
One more thing of note is when "if" style statements, which are probably things no one wants to encourage (not
even me), but it is worth exploring for more insights into parser construction (and also, if making a language, one
wants to get the finer details right).
If using the supplied example parser "multi-if" statements are possible. For example:
if(x) if(y) if(z) zoo()
xoo()
In the above connection of the function calls "zoo()" and "xoo()" to if statements is not obvious. If this
is run through the example IS parser, the generated result in C-like notation is:
if(x) {
if(y) {
if(z) {
zoo()
xoo()
}
}
}
One might expect the "zoo" to belong to the "if(z)" statement, as it follows directly on the next line, but
the "xoo()" statement might be argued to be attached to the "if(x)" statement — parsing like the following instead:
if(x) {
if(y) {
if(z) {
zoo()
}
}
xoo()
}
Why is this the case for the example parser, and can we get the behaviour of the
second result if desired? In the first case, one needs to remember first, that all "if"
statements share the same indentation level, and second, the greedy nature of the PEG
parsing algorithm. The "xoo()" statement has the required indentation to make
it in a block of any of the "if" statements, but the "if(z)" statement will be the first
to attempt to consume that statement (and so will).
Is it possible to get the "xoo()" statement consumed by the first "if", "if(x)"?
I suspect so, and I will leave it as another exercise for the reader. One possible way
would be to have two "Statement" rules in the parser: one normal one, and one for
same-line statements where any statement that requires "sub statements", such as "if" and "while",
are required to also be same-line statements.In this case the "if(z)" statement in the above example
would be consumed as a single-line statement, and would then consume its children as single-line statements, but
"xoo()" would not fall under this category. The only "if" that would consume the "xoo()" would be the first, "if(x)",
as that statement would presumably be consumed as a normal statement (and thus free to have subsequent line statements).
Other odd behaviour
As noted above comments in the example may cause odd behaviour. In particular,
the inclusion of a comment in the indentation will lead to incorrect indentation
calculation. Thus, the following:
class Happy
/*Comment*/ function happy()
is actually parsed as though it were:
class Happy
function happy()
Conversely, consider the following:
function sad()
if(x)
/*Comment*/ moo()
which is actually parsed as though it were:
function sad()
if(x)
moo()
(or in C-like notation)...
function sad() {
if(x) {
}
moo()
}
This occurs because the indentation is marked by the comment (which starts at the start of
the line). Subsequent indentation is ignored. It may be possible to change the
Java code in particular to accomodate this, but I do not see the point. I'd just
make a note in the language specification that this is strange use of comments
(or do not have comments that do not absorb the remainder of a line). It is debateable
what the correct indentation should be for the above examples.
Final notes
Simplifying IS parsing will be a focus of future work with AustenX. In particular the support
of variable passing to rules, and macros, will be investigated to enable code reuse and simplification.
Appendix 3 : error handling
This section is a work in progress, and is not finished yet!
In this section I will try and examine possible techniques for error handling and recovery. This
section focus on syntax not semantic parsing (which is the user's concern, not AustenX's), and will
use a Javascript inspired language to explain the ideas (eg, C-like, with a "function" keyword). This
side of AustenX is still a work in progress and to be honest I do not have all the answers, and
some of the ideas presented here are probably more effort than they are worth. The give inspiration
to better work though.
Downloading the example
The example files as source and binaries can be downloaded from here.
The task at hand
For this section we will work with a language that looks like the following:
function example(x,y) {
moo(x+4,5);
y = x+5;
if(x) {
print("X:"+x);
} else {
x = y;
}
}
function moo(w,z) {
z=4+w*3;
print("W:"+w);
}
That is pretty much all the language features of this language. (Semi-colons at the
end of statements are required). The above should parse. What
we care about here is what happens when various syntactical aspects become invalid? Can we
create a parser that picks up more than one problem in a single pass?
Basic error handling
By default, AustenX has a simple error handling method for when there are tokens that
cannot be consumed. This happens when no rules are available to consume all the input. If
this happens, an error is reported to the user, with the token last checked. This last checked
token is often the token where the problems has occured, because it comes from the best
rule for matching some tokens, that failed to find a suitable token at a particular point. For example:
function error1(first, --/) {
}
We have a rule for reading function definitions which looks a little like:
pattern FunctionDef (
@FUNCTION_KEYWORD:keyword ID:name LEFT_ROUND
{ ID:p / COMMA_SYMBOL } ?
RIGHT_ROUND
...
To be continued